こんにちは。kimihiro_nです。
今回はプロダクトで使用しているデータベース(MySQL 互換)を AWS から Google Cloud に引っ越ししたときのはなしを紹介します。
AWSから Google Cloud へ
AWS では MySQL 5.7 互換の Aurora グローバルデータベースを利用していました。
グローバルデータベースを使っているのは、大規模災害時におけるリージョンレベルでの障害に備えるためのもので、万一リージョンレベルの障害が発生してもサービス継続できるような体制を作っていました。
今回ある事情から Google Cloud の CloudSQL へのお引っ越しを行い、同じようにホットスタンバイでのマルチリージョン構成を構築することになりました。
なぜ AWS から Google Cloud に
恐らく一番気になるのがこの理由の部分かもしれませんが、大人の事情ということで詳細は伏せさせてください。
大きな理由としてはコストなのですが、Google Cloud に移行した方が絶対的に安くなるというわけではないので、いろいろ総合的な判断をした結果ということになります。
データ基盤が BigQuery 上で構築されていて連携がしやすいみたいな分かりやすいメリットもあります。
ちなみに Aurora は2017年くらいから利用していますが、ここ数年データベース由来での障害が発生していないので非常に優秀なデータベースサービスだと思います。
AWS から Google Cloud に移行する上での調査
どちらも MySQL 互換とはいえ Aurora と Cloud SQL では仕組みに違いがあります。
違いについてはこちらの Google Cloud 公式のドキュメントに既にまとまっていたので、こちらをよく確認し問題がないかを検証しました。
ここでの一番の懸念点はパフォーマンスでした。Aurora は独自にチューニングされて高いスループットが出るようになっているため、移行した途端データベースが悲鳴をあげてしまうことが考えられました。とはいえパフォーマンスのうたい文句などから推測で判断することも難しいです。
なので実際 Cloud SQL に建てたデータベースを用意してLocustを用いた負荷試験を実施しました。シナリオ自体は以前にDBの負荷をみるために作ったものがあったので、今回はそれを流用し Aurora に繋いだときと Cloud SQL に繋いだときとでレスポンスタイムの比較を行いました。結構重めのクエリも入っていたのですが Aurora のときと大して遜色なく捌く事ができて一安心でした。
プライマリ↔レプリカ間の同期ラグについても検証してみましたがこちらも許容範囲内でした。
どうやって移行したか
移行可能ということが確かめられたので実際の移行手順について検討をしていきました。
移行する上での前提
災害・事件・事故といったリスク情報を速く伝えるサービスなので、ユーザーが利用できなくなってしまう時間は極力減らしたいです。とはいえ完全に無停止でやろうとすると移行の工数と難易度が跳ね上がってしまうため、メンテナンスの事前アナウンスをしつつ短いダウンタイムで移行できるような方針を検討したいです。
ダウンタイムに関連する話ですが、データベースには毎秒かなりの数の書き込み操作が行われています。そのため新旧データベースを動かしながら無停止で乗り換えるみたいな事が難しく、データの不整合を避ける意味でも短時間の書き込みの停止は許容するようにしました。ニュースなどの取り込みはDBに書き込む前にキューを活用していたので、切り替え中の時間帯のニュースも取りこぼすことなく取り込みが可能です。
データベースは読み書きが可能なプライマリと読み取り専用のレプリカの複数台構成になっていて、サービスの主機能はほぼ読み取り専用のデータベースから取得しています。そのため、プライマリDBへの接続を一時停止してもエラーで何もできないといった状況は回避できるようになっていました。
データベースのサイズは数百GBほどあります。数TBとかそういった規模ではないのは幸いですが、それでもサッとコピーして終わる規模でもありません。
Aurora のデータベースは VPC 内に配置してあり、データベースを利用するアプリケーション(ECS、 Lambdaなど)もVPC内に配置して接続出来るようにしています。今回アプリケーションの Google Cloud への移行は行わず、データベースの移行だけを行うことを目的としています。そのため Cloud SQL と AWS の VPC をどう接続するかも考える必要がありました。
移行方針
上記のような前提から、このような方針ですすめることにしました
- Cloud SQL へレプリカを構築し、アプリケーションの読み込み系統をまず移行する
- 書き込み系統の移行は事前に顧客周知を行い、メンテナンス時間を設けて移行する
- AWS と Google Cloud は VPN を構築し相互に通信できるようにする
データベースの読み込み系統(レプリカへのアクセス)と書き込み系統(プライマリへのアクセス)の2段階にわけて移行する方針としました。
先にレプリケーションを利用して Cloud SQL の方にデータベースを用意しておき、Readerへアクセスしていたアプリケーションをすべて移行してしまいます。このときはレプリカからレプリカへの切り替えなので無停止で実行が可能です。
次にアプリケーションの書き込みも Cloud SQL へ向けるよう切り替えを行います。このときは不整合を防止するためサービスの書き込みを一時停止してアプリケーションの切り替え作業を行います。メンテナンス中も読み込み系統は生きているためサービスの閲覧などはそのまま利用が可能です。
この移行作業を行うにあたり、Database Migration Service(DMS) というサービスを活用することにしました。
Google Cloud の機能として用意されているマイグレーション用の仕組みで、既存の DB から簡単にレプリカを生成することができます。動きとしては手動で MySQL のレプリカを作成するのを自動化したものに近くて、「Cloud SQLの立ち上げ」「mysql dumpの取り込み」「dump以降のリアルタイムな差分取り込み」をやってくれます。今回は MySQL 互換同士でしたが、異なるデータベース種別間でも移行が可能になっているみたいです。
また、データベースのネットワークに関しては VPN を構築することにしました。
移行に際し VPC 内からデータベースアクセスを行う構成を崩したくなかったため、AWS と Google Cloud 間に VPN を構築して相互にやりとりできるようにしました。冗長な構成にもみえますが DB 移行後にアプリケーションも Google Cloud へ移行していくことを想定したときに、同じネットワークとして扱えるメリットが大きかったのでこのようにしています。
移行
VPN 構築
まず始めに Google Cloud ↔ AWS間のVPN構築するところから実施しました。
こちらの記事を参考に Terraform で VPN の HA 構成を取っています。
VPN 以外にもサブネットやルーティングの設定が必要で手こずりましたがなんとか相互で通信する事ができるようになりました。
DBのエンドポイントにドメインを割り当て
今回アプリケーションのデータベース切り替え作業にあたり、DNSを用いて切り替えが簡単にできるようセットアップを行いました。
プライマリ用とレプリカ用のホストにそれぞれ固有のドメインを割り当て、ドメインの向き先を変えることでアプリケーションの接続先も追従するようにしました。
こうすることで ECS、Lambda にあるアプリケーションを再デプロイしたりせずに切り替えができます。
また Cloud SQLでは Aurora のような接続エンドポイントが提供されず、インスタンスの IP を指定して接続する形なのでドメインを割り当てておくことでラウンドロビンをしたりもできるようになります。
Route 53 を使って読み込み系統用、書き込み系統用のドメインを作成し、CNAME で Aurora のエンドポイントを指定しました。
DNS で切り替える際の注意としては、アプリケーション側でデータベース接続を維持していると、DNS の向き先が切り替わった事を知らないまま古い DB に接続し続けてしまうことがあるので、一定時間で再接続するよう設定しておく必要があります。
Database Migration Service起動
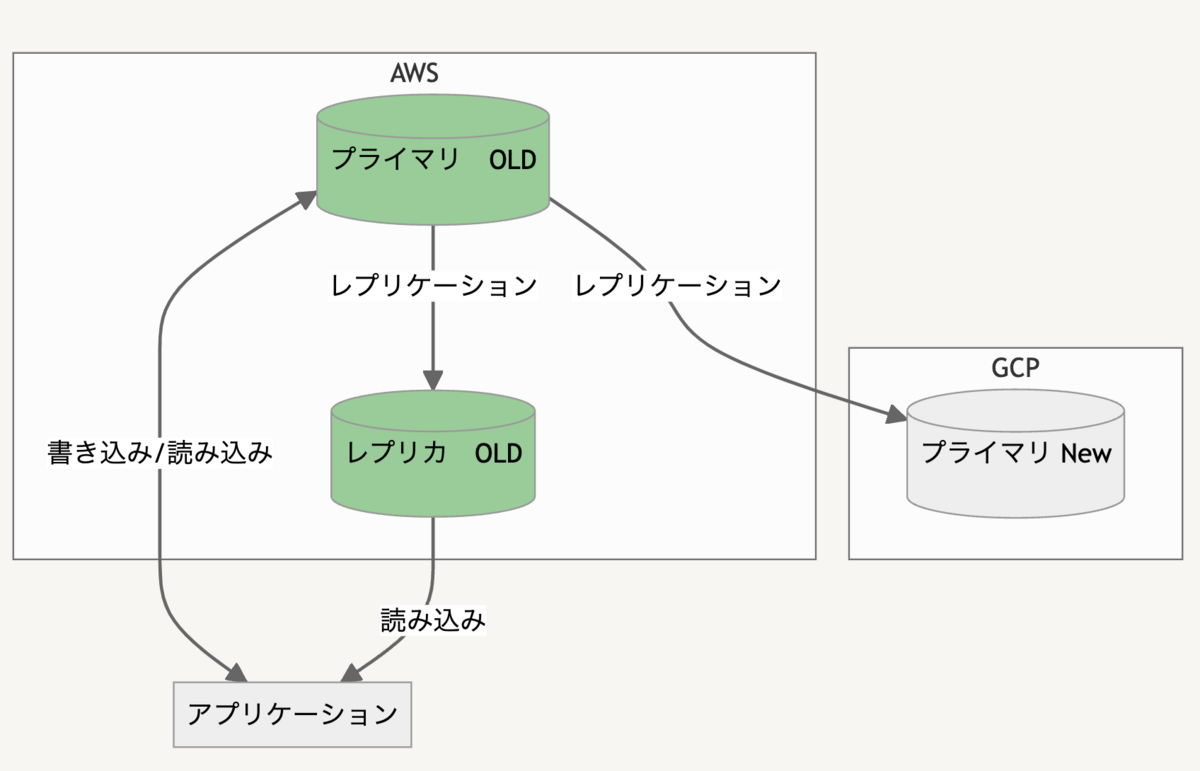
DMS を利用して Google Cloud に レプリカ を立ち上げます。VPN 構築済みなので、あとは DB の接続情報を入れるくらいで自動でレプリカインスタンスを作ってくれます。
RDS からの移行の場合、mysql dump を開始するときに一時的にプライマリの書き込みを停止する必要があり、このとき作業込みで5分くらいの書き込みダウンタイムが発生します。
それ以外はほぼ全自動で、ダンプの取り込みが完了すれば読み込み専用データベースとして利用できるようになります。取り込みの速度はだいたい100GB/時間ほどでした。
読み込み系統切替え
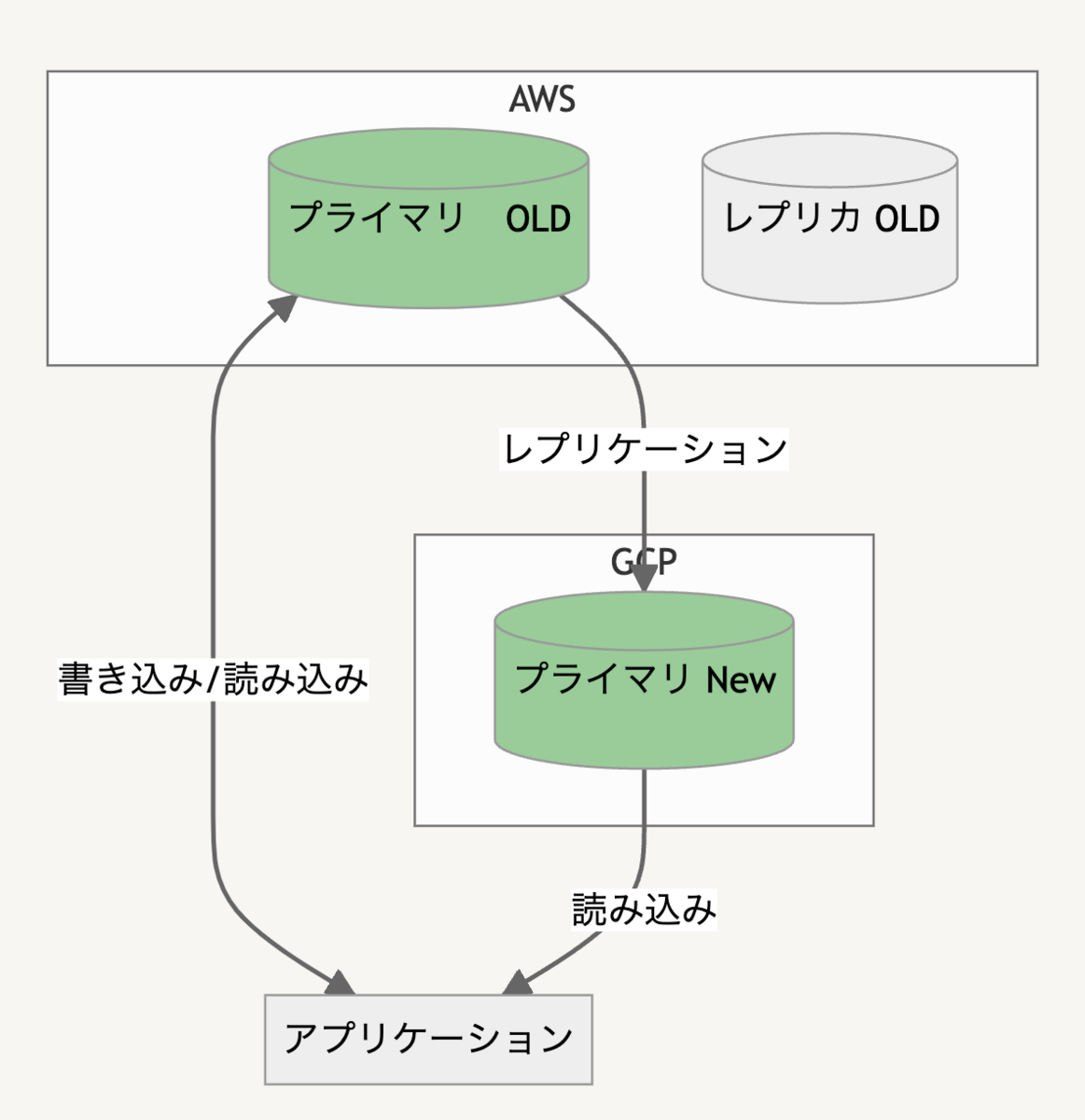
Cloud SQL にレプリカができたので、読み込み系統をまず移行します。Route 53のドメインを切り替えるだけなのですが一つ大きな問題があります。
DMS では MySQL の接続ユーザーは同期されないため、そのまま接続しようとしても認証に失敗してしまいます。
Database Migration Service 実行中はデータベースも読み取り専用になっていて困っていたのですが、Cloud SQL のコンソールから接続ユーザーが作れる事が分かったので、そちらを利用して既存の接続情報を移植しました。なおコンソールから作成したユーザーは root 権限がついてしまうのであとで権限を修正するなどの作業が必要です。
書き込み系統切替え
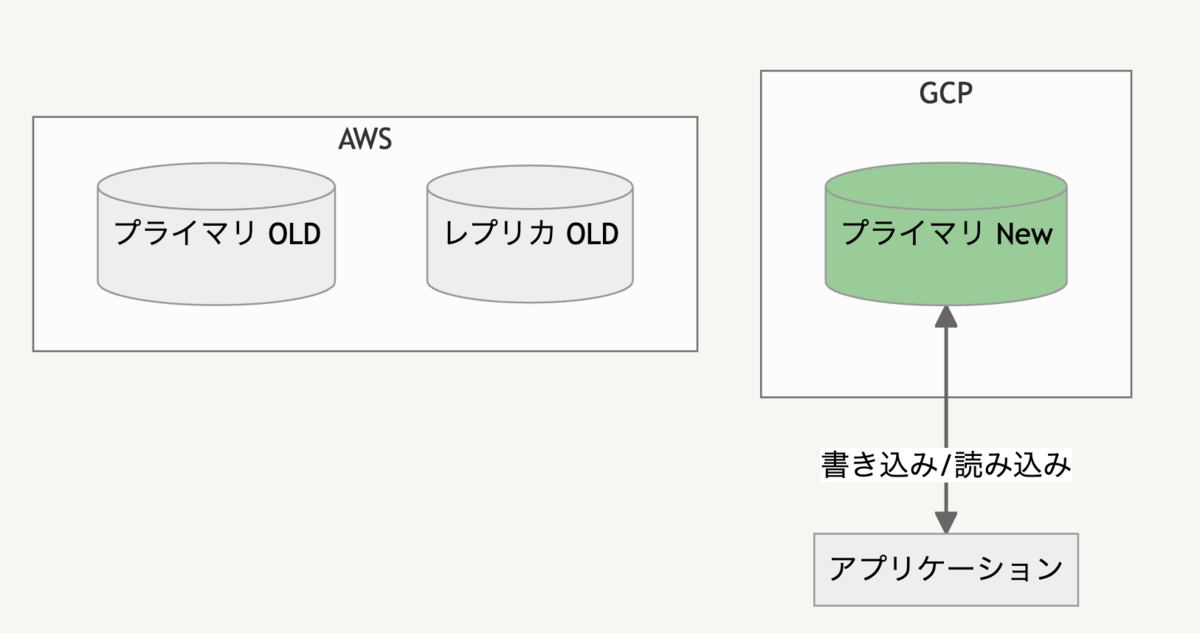
DB 移行の大詰めである書き込み系統の移行です。DMS の管理画面で「プロモート」を実行するとソースのデータベース(ここではAWS)から切り離され、独立したプライマリの DB として利用できるようになります。このとき5分ほどのダウンタイムが発生します。
無事プライマリが起動したことを確認したらアプリケーションを Google Cloud 側に切り替えて移行が完了です。
レプリカ作成
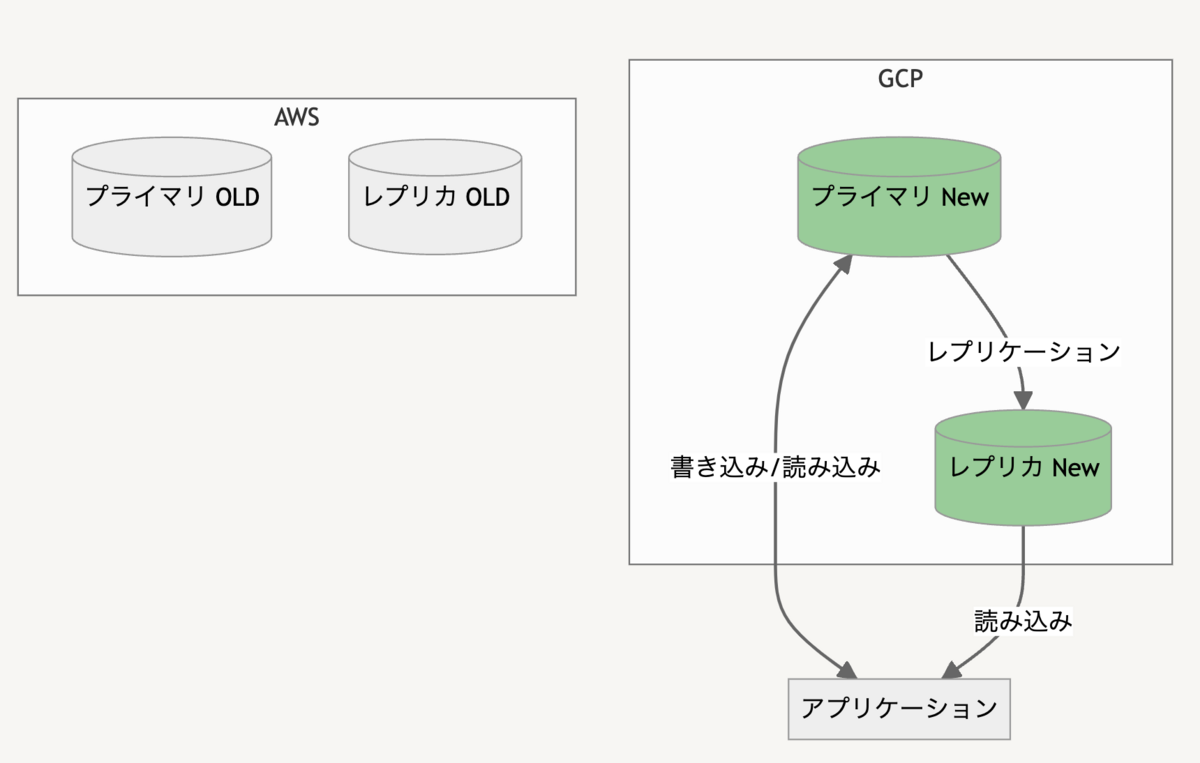
最後に Google Cloud 側にレプリカを構築して AWS のときと同じような構成に戻します。読み込み系統切替えの時点で Google Cloud 側にもレプリカを用意しておきたかったのですが DMS の管理下にあるときはレプリカの作成などができないため、移行が完了してからレプリカを構築しています。
読み込みがヘビーな場合は一時的に強めのインスタンスにして移行する必要があるかも知れません。
また、図には記載していないですがリージョンレベルの障害に備えるため別リージョンに置いたレプリカも別途用意しています。Google Cloud の場合 VPC をリージョンをまたいで構築できるのでとても簡単でした。
おわりに
DMSを活用することで DB 移行の手間を大幅に減らすことができたように思います。気がかりだったサービスのダウンタイムも、ダンプ取得時の5分と書き込み系統移行時の5分くらいと短時間で完了することができました。
移行時の大きなシステムトラブルもなく一安心です。
データベースをそっくり移行する機会はなかなかないと思いますが参考になったら幸いです。