「JX通信社Advent Calendar 2019」11日目の記事です.
昨日は, @shinyoke さんの「PySparkはじめました - 分散処理デビューする前にやったこと」でした。
こんにちは. 同じくJX通信社でデータ基盤エンジニアをしています, @maplerと申します。
はじめに
今回はちょっと美味しい話をします。
昼時間になったらよくある話
「今日昼飯どこにいきますか?」
「わからない。。」
JX通信社オフィスがある飯田橋周辺美味しい店たくさんありまして、どこでランチを食べればいいのかわからない。
ちょうど2年前、Moves App というライフログアプリを一年半ほど利用してたので、そのデータを利用して自分の飯田橋ランチマップを作ってみようと思います。
やったこと
- GeoPandas と GeoPy で位置情報の解析
- Mapbox + Plotly で位置情報の可視化
- Scikit-Learn で位置データのクラスタリング
- Google Place API で位置情報から地点を取得する
目次
Moves App とは
スマホのGPS位置情報を記録して、自分がどこに滞在してたか、その間の移動方法(徒歩、走る、自転車、車、電車など)をロギングするアプリです。(ちなみに、2018年7月末にサービス終了)
データを取得
Moves App がサービス終了時とともに、公式サイトから過去のトラックデータをダウンロードすることができます。行動データは JSON で格納されてます。
Moves のデータは四種類があります。
- activites: 移動中の行動タイプ(電車、歩行、自転車など)、カロリー、距離、時間などの情報。(Line data)
- places: 行動中の滞在地点、滞在時間などの情報。(Point data)
- storyline: activites と places を含め、さらに移動ルートの情報もあります。
- summary: 一日単位の行動、距離、カロリーなどのまとめ情報
今回はランチの店だけ絞りたいので、places 情報のみ扱うことにします。
places データ
まずどんなデータかを見ましょう:
// ./json/yearly/places/places_2017.json
[
...
{
"date": "20170327",
"segments": [
{
"type": "place",
"startTime": "20170326T201246+0900",
"endTime": "20170327T095023+0900",
"place": {
"id": 123456,
"name": "飯田橋駅",
"type": "home",
"location": { // 飯田橋駅
"lat": 35.702084,
"lon": 139.745023
}
},
"lastUpdate": "20170327T014641Z"
}
...
],
"lastUpdate": "20170328T020321Z"
},
{
"date": "20170328",
"segments": [
...
]
...
}
...
]
日別に segments という項目に時間順でその日行った場所が格納されている。
segment の構造
- type: activity データでは値は
place or move 2種類ありますが、places データには place のみになります
- startTime: その地点に着いた時間
- endTime: その地点から離れた時間
- place: 地点の情報
- id: 地点 id
- name: 地点名。アプリが自動判定してくれますが、手動で地点名修正ができます。自動判定と手動修正してない場合、不明で null になる
- type: アプリに定義したカテゴリ?
home: 家work: 仕事場facebook: 地点名推測情報源?facebookPlaceId: facebook の地点 Iduser: 手動で地点名を修正した場合
- location: 経度緯度の Geo 情報
- lastUpdate: segment の最後更新時間
太字でマークした項目は今回扱うデータになります
データをロード
Pandas でデータをロード
import pandas as pd
place_df = pd.read_json('./moves/moves_export/json/yearly/places/places_2017.json', orient="records")
place_df = pd.concat([place_df, pd.read_json('./moves/moves_export/json/yearly/places/places_2018.json', orient="records")])
place_df.head()
| |
date |
segments |
lastUpdate |
| 0 |
20170110 |
[{'type': 'place', 'startTime': '20170110T0104... |
20170117T055308Z |
| 1 |
20170111 |
[{'type': 'place', 'startTime': '20170110T2136... |
20170112T022810Z |
| 2 |
20170112 |
[{'type': 'place', 'startTime': '20170111T2035... |
20170113T163025Z |
| 3 |
20170113 |
[{'type': 'place', 'startTime': '20170112T2107... |
20170114T000927Z |
| 4 |
20170114 |
[{'type': 'place', 'startTime': '20170113T1939... |
20170114T093316Z |
直接 json ロードだと segments がうまく展開できない。
json_normalize を使ってリストのカラムを展開
json_normalize という便利な関数でカラムを展開 (flat) します。
import json
with open('./moves/moves_export/json/yearly/places/places_2017.json', 'r') as f:
d_2017 = json.load(f)
place_segment_df_2017 = json_normalize(d_2017, record_path='segments')
with open('./moves/moves_export/json/yearly/places/places_2018.json', 'r') as f:
d_2018 = json.load(f)
place_segment_df_2018 = json_normalize(d_2018, record_path='segments')
place_segment_df = pd.concat([place_segment_df_2017, place_segment_df_2018])
record_path を segments カラムを指定して展開した結果
place_segment_df.head()
| |
type |
startTime |
endTime |
lastUpdate |
place.id |
place.name |
place.type |
place.location.lat |
place.location.lon |
place.facebookPlaceId |
| 0 |
place |
20170110T010439+0900 |
20170110T094051+0900 |
20170110T013658Z |
396353386 |
家 |
home |
******* |
******* |
NaN |
| 1 |
place |
20170110T123747+0900 |
20170110T125939+0900 |
20170117T055308Z |
396514412 |
イタリアン酒場P |
facebook |
35.699011 |
139.748671 |
218228871551007 |
| 2 |
place |
20170110T130209+0900 |
20170110T195846+0900 |
20170110T113633Z |
396471967 |
JX通信社 |
work |
35.700228 |
139.747905 |
NaN |
| 3 |
place |
20170110T202923+0900 |
20170110T203906+0900 |
20170110T130729Z |
396353386 |
家 |
home |
******* |
******* |
NaN |
| 4 |
place |
20170110T204418+0900 |
20170110T212233+0900 |
20170110T160517Z |
396651896 |
エニタイムズ |
user |
35.704518 |
139.728673 |
|
※ 家の GEO情報を非表示させていただきます
データの全体像
>> place_segment_df.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 4542 entries, 0 to 1658
Data columns (total 10 columns):
type 4542 non-null object
startTime 4542 non-null object
endTime 4542 non-null object
lastUpdate 4542 non-null object
place.id 4542 non-null int64
place.name 2255 non-null object
place.type 4542 non-null object
place.location.lat 4542 non-null float64
place.location.lon 4542 non-null float64
place.facebookPlaceId 477 non-null object
dtypes: float64(2), int64(1), object(7)
memory usage: 390.3+ KB
こうして 1.5 年分ぐらいの私が行った場所が一つの DataFrame にまとめます
データを絞る (前処理)
まずはこの 4542 行のデータの中から 平日 仕事場 の ランチ を絞りたい
前処理
不要なカラムを消す
place_segment_df = place_segment_df[['startTime', 'endTime', 'place.name', 'place.type', 'place.location.lat', 'place.location.lon']]
時間カラムを datetime object に変換
place_segment_df.startTime = pd.to_datetime(place_segment_df.startTime)
place_segment_df.endTime = pd.to_datetime(place_segment_df.endTime)
平日を絞る
weekday_place_df = place_segment_df[place_segment_df.apply(lambda row: row.startTime.weekday() < 5 and row.endTime.weekday() < 5, axis=1)]
ランチ時間を絞る
時間を絞る
from datetime import timedelta
LUNCH_START_FROM = 11
LUNCH_END_FROM = 15
MAX_LUNCH_DURATION = 3 * 60
MIN_LUNCH_DURATION = 5
def is_lunch_time(start_dt, end_dt):
if end_dt - start_dt > timedelta(minutes=MAX_LUNCH_DURATION):
return False
elif end_dt - start_dt > timedelta(minutes=MAX_LUNCH_DURATION):
return False
else:
return start_dt.hour > LUNCH_START_FROM and start_dt.hour < LUNCH_END_FROM and end_dt.hour > LUNCH_START_FROM and end_dt.hour < LUNCH_END_FROM
lunch_time_place_df = weekday_place_df[weekday_place_df.apply(lambda row: is_lunch_time(row.startTime, row.endTime), axis=1)]
時間を可視化
hour_group = pd.DataFrame({"hour": place_segment_df.startTime.apply(lambda x: x.hour)}).groupby('hour')['hour'].count()
lunch_hour_group = pd.DataFrame({"hour": lunch_time_place_df.startTime.apply(lambda x: x.hour)}).groupby('hour')['hour'].count()
from plotly.subplots import make_subplots
import plotly.graph_objects as go
fig = make_subplots(rows=1, cols=2, subplot_titles=('full time', 'lunch time'))
fig.add_trace(go.Bar(x=hour_group.index, y=hour_group),row=1, col=1)
fig.add_trace(go.Bar(x=lunch_hour_group.index, y=lunch_hour_group), row=1, col=2)
fig.show(showlegend=False)

主に 13 時前後にお昼ごはんを食べていくことが多いようです。
仕事場を絞る
位置情報扱いやすいため geopy と geopandas を使い
geopandas で DataFrame を GeoDataFrame に変換
place.location.lat と place.location.lon を代入して GeoDataFrame に変換
import geopandas
gdf = geopandas.GeoDataFrame(lunch_time_place_df, geometry=geopandas.points_from_xy(lunch_time_place_df['place.location.lon'], lunch_time_place_df['place.location.lat']))
geometry というカラムが作られます
gdf.head()
| |
startTime |
endTime |
place.name |
place.type |
place.location.lat |
place.location.lon |
geometry |
| 1 |
2017-01-10 12:37:47+09:00 |
2017-01-10 12:59:39+09:00 |
イタリアン酒場P |
facebook |
35.699011 |
139.748671 |
POINT (139.74867 35.69901) |
| 10 |
2017-01-11 13:25:15+09:00 |
2017-01-11 13:45:35+09:00 |
つけ麺 つじ田 |
facebook |
35.701441 |
139.746628 |
POINT (139.74663 35.70144) |
| 17 |
2017-01-12 12:35:05+09:00 |
2017-01-12 13:11:11+09:00 |
かつ村 |
facebook |
35.698636 |
139.753765 |
POINT (139.75376 35.69864) |
| 24 |
2017-01-13 13:09:11+09:00 |
2017-01-13 13:26:29+09:00 |
ヤミツキカリー |
facebook |
35.699180 |
139.744961 |
POINT (139.74496 35.69918) |
↑ ちなみにランチ時間を絞りでいい感じにランチの地点を絞ってくれました
geopy で飯田橋周辺 3km を絞ります
geopy の distance モジュールに geodesic という測地学的な距離を計算関数があります。
from shapely.geometry import Point
from geopy.distance import geodesic
def _distance(point_a_y, point_a_x, point_b_y, point_b_x):
return geodesic((point_a_y, point_a_x), (point_b_y, point_b_x)).meters
def distance_for_point(point_a, point_b):
"""
geodesic distance of shapely.geometry.Point object
"""
return geodesic((point_a.y, point_a.x), (point_b.y, point_b.x)).meters
DIAMETER = 3 * 1000
IIDABASHI_STATION_POINT = Point(139.745023, 35.702084)
def near_iidabashi(point):
return distance_for_point(point, IIDABASHI_STATION_POINT) < DIAMETER
gdf['is_near_iidabashi'] = gdf.geometry.apply(near_iidabashi)
プライベート情報を絞る(小声 🤫)
家がオフィスに近いので仕事場絞っても家は範囲内に入ってます、たまにランチ帰宅することもあります、ここ place.type を利用して非表示させていただきます。
>> (gdf['place.name'] == 'home').value_counts()
False 501
True 4
Name: place.name, dtype: int64
>> gdf = gdf[gdf['place.type'] != 'home']
(4回帰宅してたようです🏠)
結果を可視化
今回もっともやりたかったことです!
可視化前に
便利上、滞在時間(分)の duration カラムを追加
weekday_place_df['duration'] = weekday_place_df.apply(lambda row: (row.endTime - row.startTime).seconds//60, axis=1)
場所名を coding した name_id カラムを追加
gdf['name_id'] = gdf['place.name'].astype('category').cat.codes
Mapbox と Plotly を使って地図上可視化
Mapbox を利用するため、Mapbox の開発アカウントを登録した上、token を取得する必要があります。
詳細は Mapbox の公式ドキュメント を参照してください。
※ Mapbox は従量課金制で、Web 上の地図ロードは毎月 50,000 回まで無料です。詳細はこちら
店名(name_id)を色付けにして地図上に plot
import plotly.graph_objects as go
token = 'your mapbox token here'
fig = go.Figure(go.Scattermapbox(
mode = "markers+text",
lat=gdf.geometry.y,
lon=gdf.geometry.x,
text=gdf['place.name'].apply(lambda x: x if isinstance(x, str) else ''),
textposition = "bottom center",
hoverinfo='name+text',
hovertext=gdf.apply(lambda row: f"{row['place.name']} ({row['duration']}分)", axis=1),
marker=go.scattermapbox.Marker(
color=gdf['name_id'], colorscale='RdBu',
size=10, sizemode='area'),
))
fig.update_layout(
hovermode='closest',
mapbox=go.layout.Mapbox(
accesstoken=token, bearing=0,
center=go.layout.mapbox.Center(
lat=IIDABASHI_STATION_POINT.y,
lon=IIDABASHI_STATION_POINT.x
), pitch=0, zoom=15
),
margin=dict(l=10, r=10, t=10, b=10)
)
fig.show()

ランチマップがいい感じに出てきました。
(みずほ銀行も混在してたが、とりあえず無視)
ちなみに当時名前付けてなかった店がまだ多い
>> gdf['place.name'].isnull().value_counts()
False 279
True 146
Name: place.name, dtype: int64
無名地点は倍ぐらいあります。
無名地点の名前つけ
Geo 情報から Google Place API で名前付けを考えてますが、精度を上げるため、同じ場所多数の地点をまとめてから実行しようと思います。
Scikit-learn で Clustering
Scikit-learn に Clustering のアルゴリズムがたくさん用意してますが、今回はシンプルで距離で Clustering したいので、DBSCAN を利用します。
DBSCAN
DBSCAN (Density-based spatial clustering of applications with noise ) は、1996 年に Martin Ester, Hans-Peter Kriegel, Jörg Sander および Xiaowei Xu によって提案されたデータクラスタリングアルゴリズムである。[1]これは密度準拠クラスタリング(英語版)アルゴリズムである。ある空間に点集合が与えられたとき、互いに密接にきっちり詰まっている点をグループにまとめ(多くの隣接点を持つ点、en:Fixed-radius_near_neighbors)、低密度領域にある点(その最近接点が遠すぎる点)を外れ値とする。
from Wikipedia - DBSCAN
高密度なクラスタリングとていう点は今回の要件と合います。
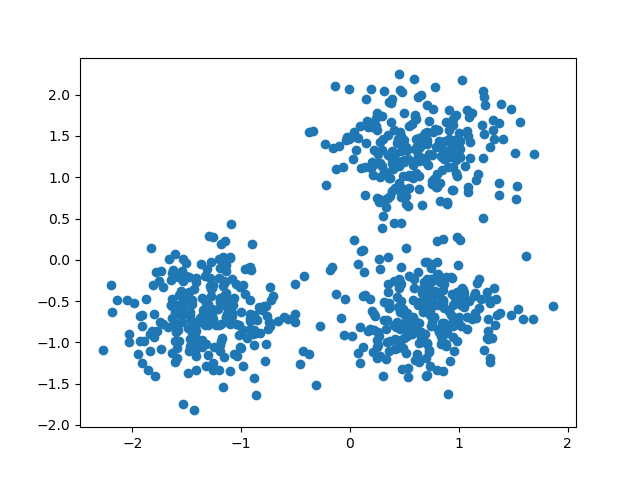
※ DBSCAN の例図(出典)
距離関数を指定して cluster を作成
上で定義した geodesic 距離関数を DBSCAN の metric 関数 として利用
5メートル範囲内に cluster を作成
from sklearn.cluster import DBSCAN
def distance_for_matrix(point_a, point_b):
"""
geodesic distance of matrix
"""
return _distance(point_a[0], point_a[1], point_b[0], point_b[1])
coords = gdf.as_matrix(columns=['place.location.lat', 'place.location.lon'])
MIN_DISTANCE = 5
db = DBSCAN(
eps=MIN_DISTANCE,
min_samples=1,
metric=distance_for_matrix
).fit(coords)
GeoDataFrame に代入
>> gdf['cluster'] = db.labels_
>> gdf['cluster'].value_counts()
6 50
4 29
24 27
5 27
12 25
..
40 1
38 1
37 1
36 1
39 1
Name: cluster, Length: 80, dtype: int64
39 クラスタ(地点)をまとまりました!
Cluster の情報を group by でまとめる
place_group = gdf.groupby('cluster')
grouped_df = pd.DataFrame({
'place_names': place_group['place.name'].apply(lambda x: list(set([x for x in x.tolist() if isinstance(x, str)]))),
'lat_mean': place_group['place.location.lat'].mean(),
'lon_mean': place_group['place.location.lon'].mean(),
'duration': place_group['duration'].mean(),
'times': place_group['cluster'].count(),
})
- place_name: アプリで判定した地点名を set unique してリスト化
- lat_mean: 緯度の平均値
- lon_mean: 経度の平均値
- duration: 滞在時間の平均値
- times: 訪問回数
テーブル整形
grouped_df.reset_index(inplace = True)
もう一回地図上で plot
group を色付けして
fig = go.Figure(go.Scattermapbox(
mode = "markers+text",
lat=gdf["place.location.lat"],
lon=gdf["place.location.lon"],
text=gdf['place.name'].apply(lambda x: x if isinstance(x, str) else ''),
textposition = "bottom center",
hoverinfo='name+text',
hovertext=gdf.apply(lambda row: f"{row['place.name']} ({row['duration']}分, {row['cluster']})", axis=1),
marker=go.scattermapbox.Marker(
color=gdf['cluster'], colorscale='RdBu',
size=10, sizemode='area')
)
)

各地点毎にいい感じに色付けしました。
Google Place API で名前つけ
クラスタリングできので、未知の地点は Google Place API を利用して、まとめて取ります。
Google MAP の Python SDK を使います。Mapbox と同じ、Google Cloud Platform の開発アカウントを登録した上、 API KEY を取得する必要があります。
詳細は Google Cloud の公式ドキュメント を参照してください。
※ Place API も同じ従量課金制(Pay-As-You-Go Pricingで、毎月 100,000 回 request まで無料です。詳細はこちら
import googlemaps
gmaps = googlemaps.Client(key='your google api key')
def get_nearby_restaurants(lat, lon, count=5):
"""
return first `count` of name of place near lat/lon
"""
ret = gmaps.places_nearby(
(lat, lon),
radius=30,
language='ja',
type='restaurant',
rank_by='prominence'
)
return [r['name'] for r in ret['results'] if r['types'][0] == 'restaurant'][:count]
places_nearby method を使って、30メートル範囲(GPS誤差を考える)内のレストランを検索して、結果の中の name をリスト化して返す。
上の未知の地点を試してみる
>> get_nearby_restaurants(35.700658, 139.741140)
['Enoteca Vita', 'アズーリ 神楽坂', '竹子', 'てんたけ', '吾']
Enoteca Vita に行ったことがないが、確かにアズーリ はめっちゃ行ってました。
GPS の誤差があるのでしょうがないことです。
Cluster の DataFrame に応用
grouped_df['predict_locations'] = grouped_df.apply(lambda row: get_nearby_restaurants(row.lat_mean, row.lon_mean), axis=1)
店名をまとめる
もともとアプリであった、place_names と Google Place API で予測した predict_locations をまとめて name という項目にまとめます。
grouped_df['name'] = grouped_df.apply(
lambda row: '/'.join(row['place_names'][:2]) if row['place_names'] else '/'.join(row['predict_locations'][:2]), axis=1
)
おれおれの飯田橋ランチマップ
データを全部揃ってきたので、いよいよ自分のランチはどんなっているのかを掲示していきます。
まずひとつの DataFrame にまとめます。
my_lunch_map_df = grouped_df[['name', 'lat_mean', 'lon_mean', 'duration', 'times', 'predict_locations']]
可視化したランチマップ最終形態
訪問回数を点の半径 size にして、店名を付けるようにしました
fig = go.Figure(go.Scattermapbox(
mode = "markers+text",
lat=my_lunch_map_df["lat_mean"],
lon=my_lunch_map_df["lon_mean"],
text=my_lunch_map_df['name'],
textposition = "bottom center",
hoverinfo='name+text',
hovertext=my_lunch_map_df.apply(lambda row: f"{row['name']} ({row['duration']}分)" if row['times'] > 1 else '', axis=1),
marker=go.scattermapbox.Marker(
color=my_lunch_map_df.index,
size=my_lunch_map_df['times'],
sizeref=0.2,
sizemode='area',
colorscale='RdBu',
),
)
)

※ (こちらはスクリーンショットだけですが、実際 Notebook 上は Mapbox で拡大で、かぶるところの店名も表示されます)
1. 回数をソートしてわかること - 偏食?
my_lunch_map_df.sort_values('times', ascending=False).head(10)
| |
name |
lat_mean |
lon_mean |
duration |
times |
predict_locations |
| 0 |
刀削麺 火鍋 XI'AN |
35.698675 |
139.745555 |
26.720000 |
50 |
[芊品香 別館, うなぎ川勢, X'IAN飯田橋, 居酒屋・秋刀魚, 鳴門鯛焼本舗 飯田橋駅前店] |
| 1 |
ヤミツキカリー |
35.699180 |
139.744961 |
17.793103 |
29 |
[魂心家 飯田橋, 東京餃子 あかり 飯田橋, 鳥貴族 飯田橋西口店, Yamitukiカリ... |
| 2 |
JX通信社 |
35.700228 |
139.747905 |
30.555556 |
27 |
[大阪王将 飯田橋店, 蕎庵 卯のや, BAR de Cava] |
| 3 |
たい料理 ロッディー |
35.700607 |
139.745326 |
21.703704 |
27 |
[太郎坊, ロッディー] |
| 4 |
Enoteca Vita/アズーリ 神楽坂 |
35.700658 |
139.741140 |
39.600000 |
25 |
[Enoteca Vita, アズーリ 神楽坂, 竹子, てんたけ, 吾] |
| 5 |
イタリアン酒場P/エニタイムズ |
35.699011 |
139.748671 |
27.208333 |
24 |
[イタリア料理 LUCE ルーチェ, イタリア酒場P, やきとり あそび邸 飯田橋, 美食処... |
| 6 |
天こう餃子房 |
35.701035 |
139.746305 |
25.136364 |
22 |
[築地食堂源ちゃん 飯田橋店, テング酒場 飯田橋東口店, 土間土間 飯田橋東口店, 牛角 ... |
| 7 |
鳥酎 飯田橋 |
35.700951 |
139.746536 |
26.000000 |
21 |
[テング酒場 飯田橋東口店, 土間土間 飯田橋東口店, ル・ジャングレ, 牛角 飯田橋東口店... |
| 8 |
牧の家/旬味福でん |
35.699635 |
139.746270 |
19.250000 |
20 |
[牧の家, 旬味福でん, 島] |
| 9 |
アジアンダイニング puja |
35.699137 |
139.748516 |
25.111111 |
18 |
[イタリア料理 LUCE ルーチェ, 時代寿司, イタリア酒場P, やきとり あそび邸 飯田... |
刀削麺めっちゃ食べてる?!
2位であるタイ風カレーの ヤミツキカリー もある時期毎日行ってた記憶があります。
JX通信社オフィスが3位!ある時期自炊して弁当を作ることがあったので、会社で食べることがわりと多かった(間違えってまとめてた可能性もあります)
8 位 predict_locations にある島という沖縄料理にあたると思います
偏食諸説?
総合でみると、中華 (刀削麺 + 餃子房) 72 回、タイ + インド 74 回というのが年中半分以上の昼飯はこの2種類になってますので、偏食している自分を見つかったかもしれない?
2. 滞在時間をソートしわかること - シャッフルランチ制度
滞在時間長いが、ランチではない場所も出てきたので、一回レストラン名が取れなかったものをフィルタリングします
my_lunch_map_df[my_lunch_map_df['name'].apply(lambda x: bool(x))].sort_values('duration', ascending=False).head(10)
| |
name |
lat_mean |
lon_mean |
duration |
times |
predict_locations |
| 46 |
別亭 鳥茶屋/メゾン・ド・ラ・ブルゴーニュ |
35.700753 |
139.74074 |
73.000000 |
1 |
[別亭 鳥茶屋, メゾン・ド・ラ・ブルゴーニュ, アズーリ 神楽坂, 個室割烹 神楽坂 梅助... |
| 65 |
神楽坂イタリアン400 クワトロチェント/天空のイタリアン Casa Valeria(カーサ... |
35.701537 |
139.74016 |
48.000000 |
1 |
[神楽坂イタリアン400 クワトロチェント, 天空のイタリアン Casa Valeria(カ... |
| 44 |
九頭龍蕎麦 はなれ/リストランテ クロディーノ 神楽坂 |
35.701844 |
139.73892 |
48.000000 |
1 |
[九頭龍蕎麦 はなれ, リストランテ クロディーノ 神楽坂, 上海ピーマン, 神楽坂 新泉,... |
| 53 |
浅野屋/Sガスト 神田神保町店 |
35.695391 |
139.75954 |
45.000000 |
1 |
[浅野屋, Sガスト 神田神保町店, 本格四川料理 刀削麺 川府 神保町店, 築地食堂源ちゃ... |
| 21 |
神楽坂魚金/神楽坂 芝蘭 |
35.702051 |
139.74132 |
40.666667 |
3 |
[神楽坂魚金, 神楽坂 芝蘭, 天孝, 翔山亭 黒毛和牛贅沢重専門店 神楽坂本店] |
| 4 |
Enoteca Vita/アズーリ 神楽坂 |
35.700658 |
139.74114 |
39.600000 |
25 |
[Enoteca Vita, アズーリ 神楽坂, 竹子, てんたけ, 吾, ますだや, 다케... |
| 32 |
卸)神保町食肉センター 本店/神保町 kururi |
35.697251 |
139.75759 |
39.500000 |
2 |
[卸)神保町食肉センター 本店, 神保町 kururi] |
| 67 |
筋肉食堂 水道橋店/札幌らーめん 品川甚作本店 |
35.701428 |
139.75370 |
39.000000 |
1 |
[筋肉食堂 水道橋店, 札幌らーめん 品川甚作本店, 立ち呑み海鮮 魚升, 御麺屋 水道橋店... |
| 11 |
芊品香/和彩 かくや |
35.699369 |
139.75014 |
38.500000 |
14 |
[芊品香, 和彩 かくや] |
| 45 |
BISTROマルニ/源来酒家 |
35.695853 |
139.75458 |
37.000000 |
1 |
[BISTROマルニ, 源来酒家, CHICKEN CREW チキンクルー 神保町, 十勝ハ... |
上位に神楽坂の料亭が多く並んているようです。
ここは JX通信社のシャッフルランチという制度があります。1人あたり1,000円を会社から支給で、オフィス周辺の美味しい店でゆっくりランチを食べれます。
www.wantedly.com
神楽坂4年住まいの自分もこの機会しか神楽坂の高級レストランに行けなかった。
ごちそうさまでした!
終わりに
今回は位置情報データをいろいろ変換と可視化をやってみました。
2年ほど寝かしたデータですが、可視化してみると意外と面白かった。
本当に偏食ではないですが、頭の中に思ってたアイディア具体化できるのがいいなと感じました。
明日の「JX通信社Advent Calendar 2019」は, @andmohikoさんです.
参考文献






