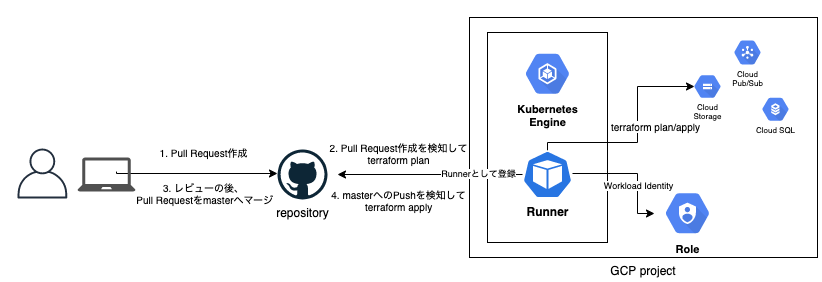
はじめに
TL; DR;
- 社内の普段はインフラ以外のところを主戦場にしている人向けに、AWS・GCPの権限に関する用語と概念を説明するために書いたものを加筆訂正して公開します
- AWS・GCPの権限管理は、基本的な概念は似ているが同じ英単語が別の意味でつかわれているのでややこしい
- 書いてあること
- 概念の説明と、関係を表す図
- EKS・GKEからクラウドリソース *1 を使う時の考え方
- 書いてないこと
- 設定のためのコンソール画面のスクショや手順
- Kubernetesからクラウドリソースを操作する方法は、以前のブログ「GitHub Actionsで実現する、APIキー不要でGitOps-likeなインフラCI/CD」でTerraformによるコードの例も紹介しているので、あわせて参考にしてみてください
想定読者
- AWSはそこそこ使って慣れているけど、GCPにおける権限管理を理解したい人(またはその逆)
- マネージドなKubernetes上でクラウドのリソースを使うときの考え方を知りたい人
なぜパッと見てややこしいのかについて、私は
- 同じ単語が異なる意味で使われている
- 似ている概念に異なる単語が当てられている
- ある目的を達成する手段が別の方法で分解されている
の3つの理由があるからだと思います。なので、本記事ではできるだけ枕詞をつけたりセクションを区切って、「何について話しているのか」を明確にしながら解説していきたいと思います。
AWSとGCP
この二者の間では、まず「Policy」および「Role」という単語が異なる意味で使われています。
Policy
AWSにおけるPolicy
- 「許可・禁止する操作(Actions)とその対象リソース(Resouces)」を表現するもの
- (例)「xxxって名前のbucketをReadしていいよ」
- (例)「
dev-で始まる名前のDynamoDBについて何でもやって良いよ、ただしテーブル消しちゃダメよ」
- つまり「操作対象と内容」についての話で、「誰が」その権限を持つかについては関知しない
- 認証(Authentication)ではなく認可(Authorization)に関係している
- 「誰」を定義するのAWSではIAM User/Group/Roleの役目
GCPにおけるPolicy
- 「操作の主体」と「操作の内容」を紐付けるもの
- 操作の主体
- (例) Googleアカウントでコンソールにログインする生身のユーザ
- (例) CloudFunctionやGCEインスタンスが使うService Account
- 操作の内容: GCPにおけるRole
- 操作の主体
- 許可する操作に「Condition(条件)」をつけることができる
- (例)「君にGCSの読み書き権限あげるけど、
hoge-stgってバケットだけね」 - (例)「アナタはBigQueryでQuery実行していいけど、日本時間の月〜金だけね」
- (例)「君にGCSの読み書き権限あげるけど、
- Webのコンソール上では
IAM & Admin > IAMで操作できる- (筆者の観測範囲では)AWSから来た人はこの辺で迷うことがよくあるみたいです
Role
AWSにおけるRole
- IAM Policyのセットをまとめて、「誰か」に使ってもらうもの
- 生身のユーザーや、Lambda/EC2/ECSなどのワークロードに、Roleを紐付けて使う(=RoleをAssumeする)
GCPにおけるRole
- 許可する操作をまとめた権限のセット
Storage Admin(project) Ownerといった名前がついている- Roleを紐付ける対象はService AccountまたはUserであり、GCE・CloudFunctionといったワークロードではない
「権限をセットにする」という意味でAWS・GCPともに似ているようですが、実際にワークロードにクラウドリソースの権限を渡す方法が微妙に異なります。では具体例で比較してみましょう。
具体例で対比して理解する
「Serverlessな関数(Lambda/CloudFunction)からオブジェクトストレージ(S3/GCS)の特定のBucketをRead onlyに使いたい」 というケースを考えてみましょう。*2
- AWSの場合は、「S3バケットを読むためのIAM PolicyをIAM Roleにつけて、そのIAM RoleをLambdaに使わせる」
- GCPの場合は、「GCSバケットを読むためのRoleをServiceAccountにつけて(=Policyの設定)、CloudFunctionsにそのServiceAccountを使わせる」
図で表すとこのようになります。

こうしてみると、 AWSにおけるPolicyは、GCPのPolicyよりもRoleの方に性格が近い かもしれません。整理すれば考え方として似通っているところもあり、決して複雑ではないのですが、こういった概念と用語の違いが「パッと見てややこしく見えてしまう」原因ではないでしょうか。
また、「オブジェクトストレージ(S3/GCS)系サービス触っていいけど、このバケットだけね」のように個別のリソース単位の制限をかけるのが
- AWSの場合はIAM Policyで可能な操作(S3の読み取り)と対象(許可する個別のバケットの絞り込み)をまとめて指定する
- GCPの場合はRoleでGCSというサービス自体の読み取り権限を定義され、それを主体と紐付ける(=Policyを定義する)ところでConditionをつけて対象のバケットを絞る
という違いがあり、(AWSからみれば)GCPでは同じことを達成するための手段が分解されているように見えます。用語の違いだけでなく、同じことを実現するための手段が違うステップに分かれていることも、最初は少し混乱してしまう理由の一つではないでしょうか。
Kubernetes上のPodからクラウドのリソースを使う場合
では、AWS・GCPのマネージドなKubernetes(=EKS/GKE)の上で動くワークロード(=Pod)から、S3/GCSなどのクラウドリソースを操作する場合を考えていきましょう。
AWS・GCPの層の上にKubernetesが乗っかり、「(Kubernetesの)ServiceAccount」という概念が出てくるので、ここまでの説明を踏まえて整理してみます。
AWSとKubernetes(EKS)
EKSからAWS上のリソースを使いたい場合は「IAM RoleとEKSクラスタ上のServiceAccountを紐付ける」が基本になります。 *3
もちろん「IAM Userを作成し、APIキーを発行して、KubernetesのSecretリソースを通してPodに持たせる」こともできますが、静的なAPIキーの発行は避けた方が良いでしょう。*4
GCPとKubernetes(GKE)
前述のEKSの場合と同様の考え方で、「GCPのServiceAccount(GSA)とGKEクラスタ上のServiceAccount(KSA)を紐付ける」が基本になります。その方法がWorkload Identityです。
GCPの世界とKubernetesの世界の両方に「Service Account」という単語が出てくることが少しややこしいので、「今どちらについて話題にしているのか」を意識しておくとよいでしょう。
Workload Identityを使うことで、静的なAPIキーを発行することなくKubernetes上のワークロード(=Pod)にGCPリソースを利用させることができます。
具体例で対比して理解する
具体例として前述のLambda/CloudFunctionsの例にならって、「EKS/GKE上のPodからS3/GCSの特定のBucketをRead onlyに使う」ケースを考えてみましょう。
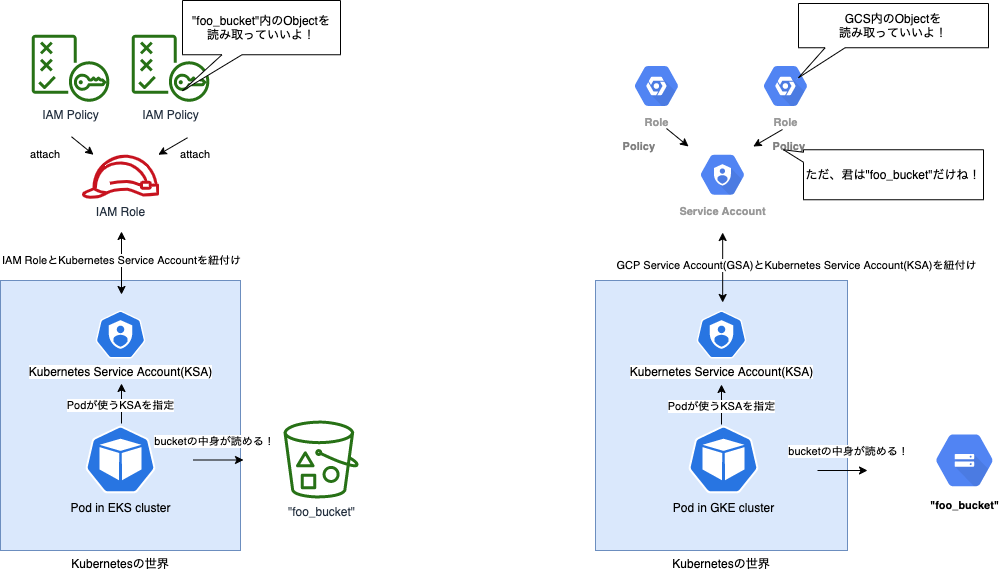
図にしてみると、非常によく似ていることがわかりますね。
まとめ
AWS・GCPおよびKubernetesの権限まわりの用語と概念を、具体例で対比しながら整理してみました。どなたかの参考になれば幸いです。
最後に
JX通信社では、PythonやGoを使って「NewsDigest」の開発に参加してくれるインターン生を募集しています! 特に、AWS・GCPの利用経験のある方は歓迎します!
*1:本記事ではS3・GCSといったオブジェクトストレージやRoute53・CloudDNSなどのDNSサービスなど、「利用するためにクラウドの権限が必要なもの」を指します
*2:厳密には、S3のBucket PolicyやGCSのACLなどBucket側の設定も存在しますが、今回はIAM側について話しているので言及しません
*3:https://docs.aws.amazon.com/eks/latest/userguide/iam-roles-for-service-accounts.html
*4:今は静的なAPIキーなしでKubernetesのServiceAccount単位でIAM Roleを設定できますが、かつてはそれが不可能でAPIキーを発行せずに権限を持たせるにはNode単位でEC2としてInstance Profile設定するしかありませんでした。この辺りの経緯や詳細は、こちらの解説がわかりやすいです https://dev.classmethod.jp/articles/eks-supports-iam-roles-for-service-accounts/