(ちょっと遅れましたが)新年あけましておめでとうございます🪁
JX通信社シニア・エンジニアで, データサイエンスからプロダクト開発までなんでもやるマンの@shinyorke (しんよーく)と申します.
Stay Homeな最近は大河ドラマを観るのにハマってます&推しの作品は「太平記」です*1 .
データ分析やデータサイエンティスト的な仕事をしていると,
「いい感じのアウトプットがでた!やったぜ!!なおプレゼン🤔」
みたいなシチュエーションが割とあると思います.
さあプレゼンだ!となったときにやることと言えば,
ドキュメントとしてまとめる. 社内Wikiやブログ, ちょっとしたスライドなど.
分析・実験で使ったモノをそのまま見せる. より具体的に言うとJupyterのnotebookそのもの.
社内のいろいろな方に伝わるよう, ちょっとしたデモ(Webアプリ)を作る.
だいたいこの3つのどれかですが, やはり難易度が高いのは「ちょっとしたデモ作り」かなと思います.
???「動くアプリケーションで見たいからデモ作ってよ!」
この振りってちょっと困っちゃう*2 な...って事はままある気がします.
そんな中, 昨年あたりからStreamlit というまさにこの問題をいい感じに解決するフレームワークが流行し始めました.
www.streamlit.io
これがとても良く使えるモノで, 私自身も,
昨年のPyCon JP 2020 など, 登壇や個人開発にてプロトタイプが必要なときに利用.*3
業務上, 「動くアプリ」を元にコミュニケーションが必要だったりプレゼンするときに利用
といった所でStreamlitを愛用しています.
とても便利で素晴らしいStreamlitをご紹介ということで,
Streamlitをはじめるための最小限の知識・ノウハウ
JX通信社の業務においてどう活用したか?
Streamlitの使い所と向いていない所
という話をこのエントリーでは語りたいと思います.
TL;DR
データサイエンティストが「アプリっぽく」プレゼンするための飛び道具としてStreamlitは最高に良い. Jupyterでできること, Webアプリでできることを両取りしてPythonで書けるのでプロトタイピングの道具として最高
あくまで「プロトタイピング」止まりなので仕事が先に進んだらさっさと別の手段に乗り換えよう
おしながき
Streamlitをはじめよう
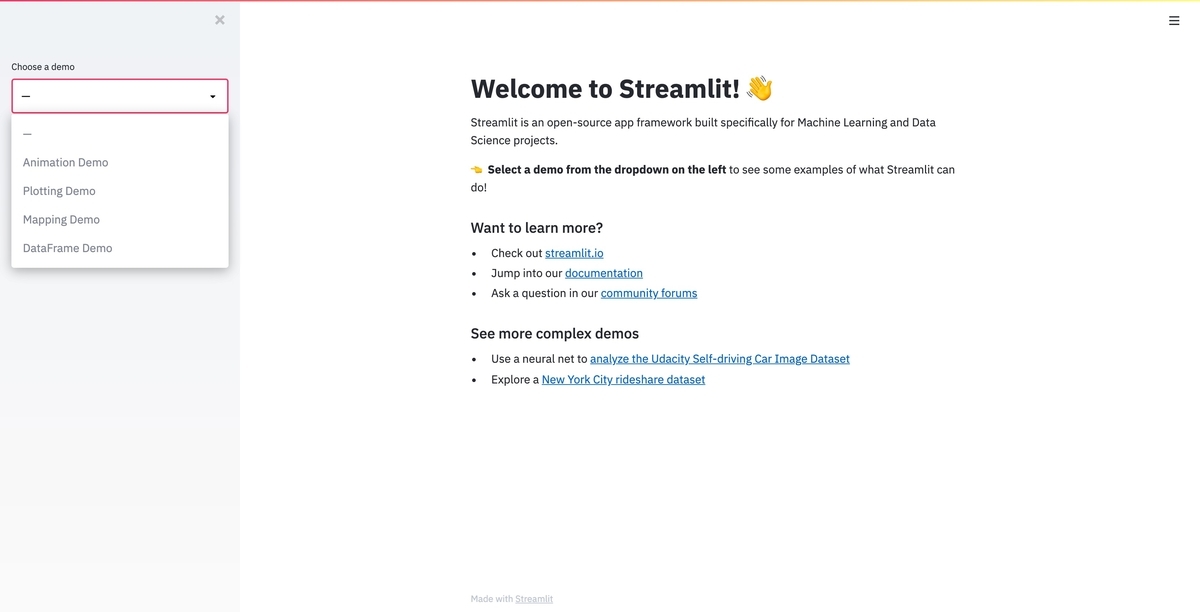
Streamlitのサイト にSample Gallery やドキュメント などかなり充実しているのでそちらを見ていただきつつ, 触りながら覚えると良いでしょう.
触ってみよう
インストールそのものはPythonのライブラリなので,
$ pip install streamlit
でいけちゃいます.
$ streamlit hello
とコマンドを叩くと, http://localhost:8501 で用意されているデモが立ち上がります.
最初はデモを触る・コードを読みながら写経・真似しながら動かすと良さそうです.
重要なポイントとしては,
Webブラウザで動く動的なアプリケーションが, .py ファイルを書くだけで動く
ことです.
Javascriptやフロントエンドのフレームワークを使ったり, HTMLやCSSの記述が不要というのがStreamlitのミソです*4 .
作って動かそう
hello worldで遊んだ後はサクッと作って動かすと良いでしょう.
...ということで, この先はイメージをつかみやすくするため,
こういうのを100行ちょいで作れます
このようなサンプルを用意しました.
github.com
サンプルの⚾️データアプリを元に基本となりそうなところを解説します.
README.md に設定方法・動作方法があるので手元で動かしながら見ると理解が早いかもです.
(venv) $ streamlit run sample_demo.py
pandas.DataFrameを出力する
pandasに限らず,
何かしらのテキスト
何かしらのオブジェクト(グラフなど)
もそうなのですが, st.write(${任意のオブジェクト}) でいろいろなモノをブラウザで閲覧できるモノとして表示ができます.
たとえば,
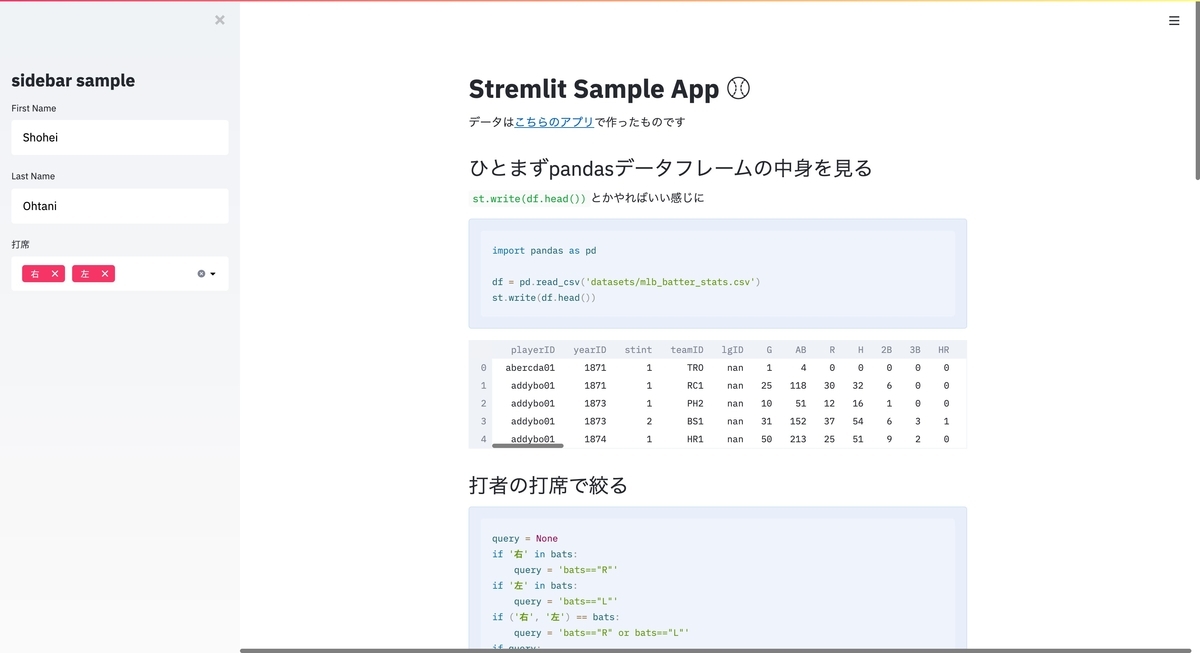
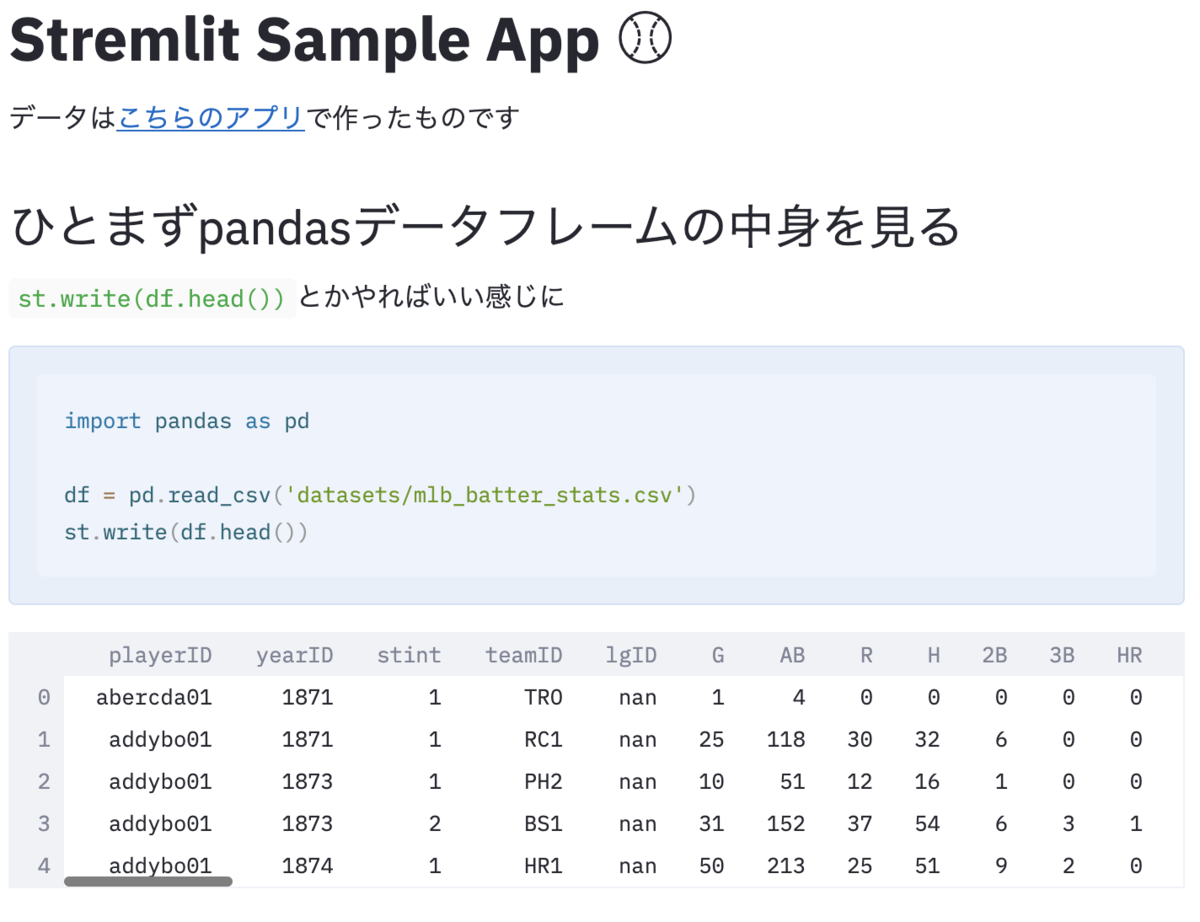
st.write('# Stremlit Sample App :baseball:' )
st.write('データは[こちらのアプリ](https://github.com/Shinichi-Nakagawa/prefect-baseball-etl)で作ったものです' )
st.write('## ひとまずpandasデータフレームの中身を見る' )
st.write('`st.write(df.head())`とかやればいい感じに' )
import pandas as pd
df = pd.read_csv('datasets/mlb_batter_stats.csv' )
st.write(df.head())
こちらはこのように表示されます.
※sampleのこの辺 です.
作成中・試行錯誤の状態はこのような形でprint debugっぽいやり方でやると良さそうです.
入力フォームを使う
入力フォームもいい感じに作れます.
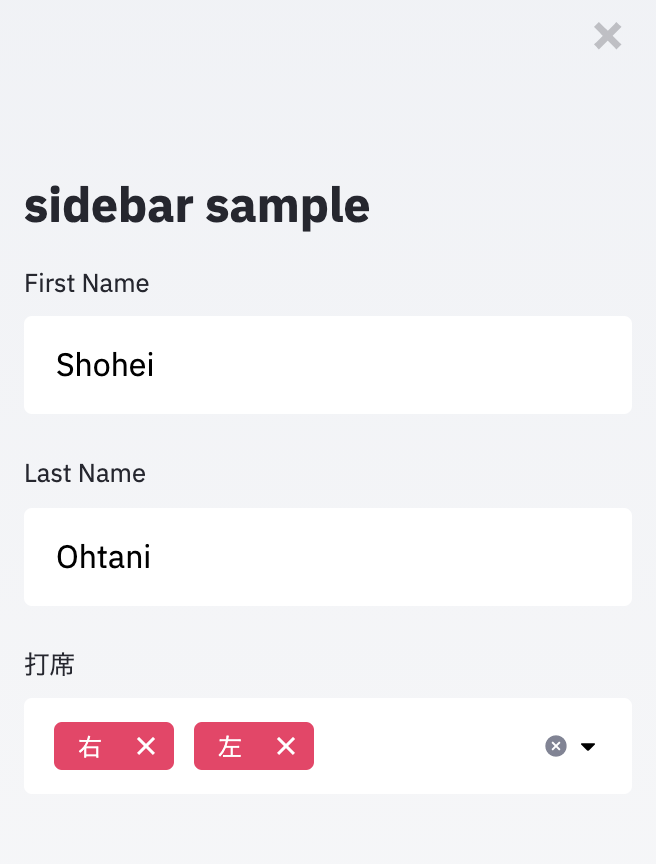
st.sidebar.markdown(
"""
# sidebar sample
"""
)
first_name = st.sidebar.text_input('First Name' , 'Shohei' )
last_name = st.sidebar.text_input('Last Name' , 'Ohtani' )
bats = st.sidebar.multiselect(
"打席" ,
('右' , '左' ),
('右' , '左' ),
)
上記はこのような感じになります.
今回はsidebarという形で横に出しましたが, team_name = st.text_input('Team Name', 'Hanshin') という感じで, sidebarを介さず使うとページ本体に入力を設けることもできます.
フォームで入れたモノはこのように使えます.
st.write('## 打者の打席で絞る' )
query = None
if '右' in bats:
query = 'bats=="R"'
if '左' in bats:
query = 'bats=="L"'
if ('右' , '左' ) == bats:
query = 'bats=="R" or bats=="L"'
if query:
df_bats = df.query(query)
st.write(df_bats.head())
※sampleのこの辺 です.
これだけで, DataFrameをインタラクティブに使うアプリケーションが作れます.
グラフを描画する
また, 好きなライブラリでグラフなどを描画できます.
私はよくplotly を好んで使うのですが,
import plotly.graph_objects as go
def graph_layout (fig, x_title, y_title):
return fig.update_layout(
xaxis_title=x_title,
yaxis_title=y_title,
autosize=False ,
width=1024 ,
height=768
)
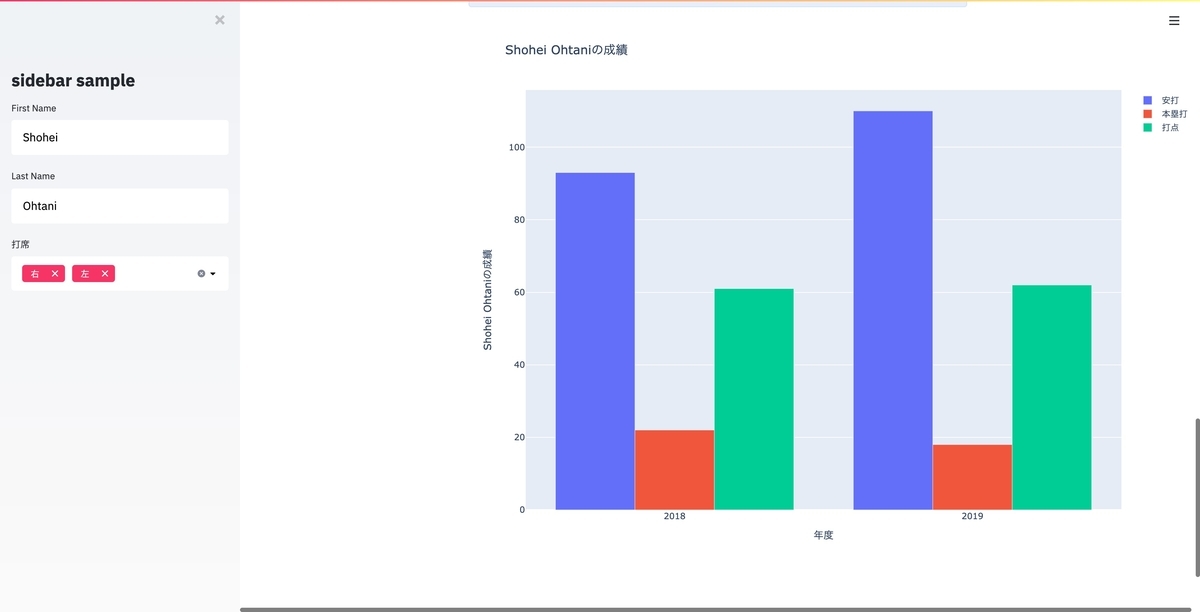
title = f'{first_name} {last_name}の成績'
fig = go.Figure(data=[
go.Bar(name='安打' , x=df_query['yearID' ], y=df_query['H' ]),
go.Bar(name='本塁打' , x=df_query['yearID' ], y=df_query['HR' ]),
go.Bar(name='打点' , x=df_query['yearID' ], y=df_query['RBI' ])
])
fig = graph_layout(fig, x_title='年度' , y_title=title)
fig.update_layout(barmode='group' , title=title)
st.write(fig)
このコード はこうなります.
これをWebのちゃんとしたアプリで実装するのは苦労するのですが, ちょっと見せるレベルのモノがこれだけでできるのは感動モノです.
Streamlitを仕事で使う
実際の業務での活用ですが, 私の場合は以下のイメージで使っています.
実務でやってること(図)
より具体的には,
まずはJupyterLabやGoogle Colabといった手段(どっちもJupyterが中心)でタスクをこなす
こなしたタスクがいい感じになったらStreamlitでデモアプリを開発
Streamlitで作ったデモでプレゼンを行い, チームメンバーからのフィードバックをもらう
というフローで活躍しています.
そもそもJupyterがアプリを作るのに向いてない所を補完するのがStreamlitの役割なので書き換えはすごく楽です.
JupyterからStreamlitへの書き換え(と比較)については, 以前こちらのエントリーに書いた のでご覧いただけると雰囲気がつかめると思います.
shinyorke.hatenablog.com
また, 「チームメンバーからのフィードバックをもらう」という意味では, 無味乾燥なセルでしかないJupyter(含むColab)よりも,
簡易的とはいえWebのアプリケーションとして見せることができるので, データサイエンティスト・エンジニア以外のメンバーにも伝わりやすい
という長所があります.
みんなで触る
(Streamlitに限った話ではありませんが)手元でWebアプリを動かせるということは, ngrok など, 手元にあるアプリをproxyできる仕組みでチームメンバーに触ってもらいながらフィードバックをもらうことができます.
Streamlitの場合, デフォルトの設定だとhttp://localhost:8501 というURLが振られる(8501でhttpのportが使われる)*5 ので,
$ # すでにstreamlitのアプリケーションが8501で立ち上がってると仮定して
$ ngrok http 8501
これで払い出されたURLを用いることにより, MTGの最中など限定されたシチュエーションで触ってもらいながら議論したりフィードバックをもらうことが可能となります.
様々な理由で決して万能とは言えない方法でもあったりします*6 が, リモート作業・テレワーク等で離れた所にいても実際に見てもらいやすくなるのでこの方法はとても便利です.
Streamlitが不得意なこと
ここまでStreamlitの使い所・得意な事を網羅しましたが, 苦手なこともあります.
複数ページに跨るアプリケーションを作ること. 例えば, 「入力->確認->完了 」みたいな複数ページの登録フォームを作るのは苦手(というよりできないっぽい).Streamlitのデザインから変更して見た目を整える. 例えば, 「(弊社の代表アプリである)NewsDigestっぽいデザインでデモ作ってくれ」みたいなのは辛い.
The fastest way to build and share data apps(データを見せるアプリを爆速で作るのにええやで) と謳っているフレームワークである以上, ガチのWebアプリなら考慮していることを後回しにしている(かつこれは意味意義的にも非常に合理的と私は思っています)関係上, 致し方ないかなと思います.
なお私の場合はこの長所・短所を把握した上で,
Streamlitに移植する段階である程度コードをクラス化したりリファクタリング(含むテストコードの実装)を行い, 将来のWebアプリ・API化に備える
上記でリファクタリングしたコードをそのままFastAPIやFlaskといった軽量フレームワークでAPI化する
といった方針で使うようにしています.
アジャイルなデータアプリ開発を
というわけで, 「データサイエンティストがアプリを作る飛び道具としてStreamlit最高やで!」という話を紹介させていただきました.
最後に一つだけ紹介させてください.
私たちは、ソフトウェア開発の実践
あるいは実践を手助けをする活動を通じて、
よりよい開発方法を見つけだそうとしている。
この活動を通して、私たちは以下の価値に至った。
プロセスやツールよりも個人と対話を、
包括的なドキュメントよりも動くソフトウェア
契約交渉よりも顧客との協調を、
計画に従うことよりも変化への対応を、
価値とする。すなわち、左記のことがらに価値があることを
認めながらも、私たちは右記のことがらにより価値をおく。
※アジャイルソフトウェア開発宣言 より引用
「機敏(Agile)に動くもの作ってコミュニケーションとって変化を汲み取り価値を作ろうぜ!」というアジャイルな思想・スタイルで開発するのはエンジニアのみならずデータサイエンティストも同様です, XP(eXtreme Programming)はデータサイエンティストこそ頑張るべきかもしれません.
そういった意味では, データサイエンティストが使うPythonやその他のエコシステムも「スピード上げて開発して価値を出そう!」という所にフォーカスが当たり始めているのは個人的にとても嬉しいですし, こういった「アジャイルな思想の道具」を使って価値を出していくのは必須のスキルになっていくのではとも思っています.
このエントリーがデータサイエンティストな方のプロトタイプ開発に役立つと嬉しいです.
最後までお読みいただきありがとうございました, そして本年もどうぞよろしくお願いいたします🎍