JX 通信社のフロントエンドでは React TypeScript や Emotion のような CSS in JS を技術選定することが多いです。弊社 SaaS の FASTALERT、新型コロナ関連情報などでも同様の技術選定で、過去にもエンジニアブログで紹介してきました。
今日は、Emotion の活用の極地「Utility First な CSS in JS フレームワーク」についてご紹介します。
Emotion で開発する悩み
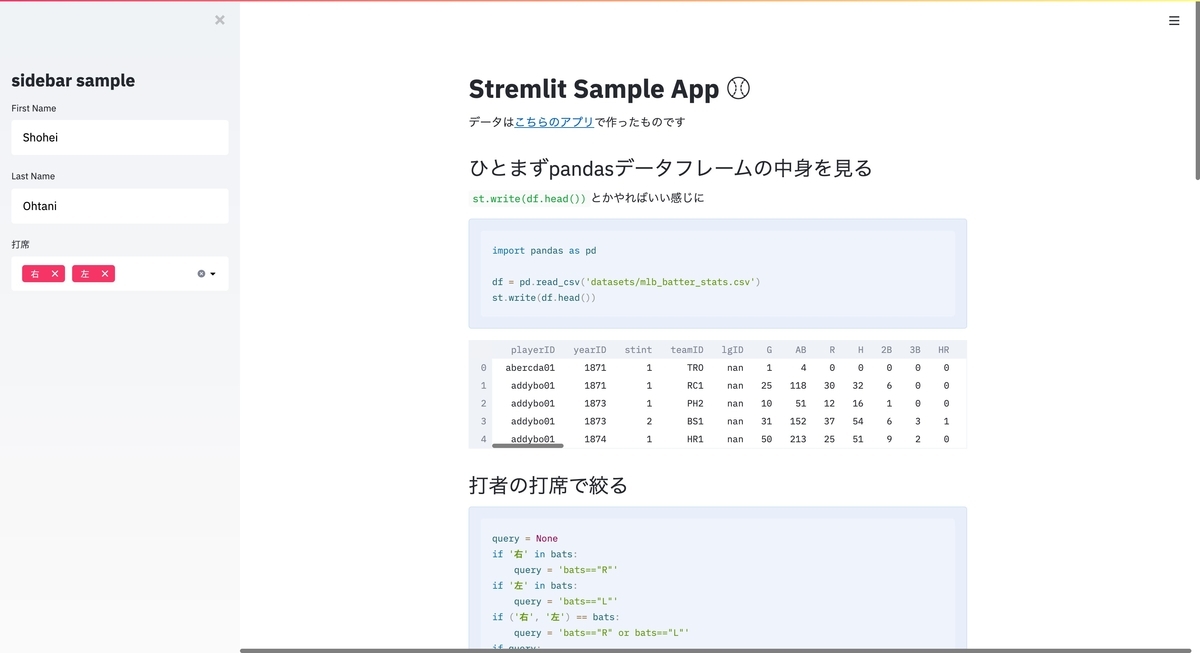
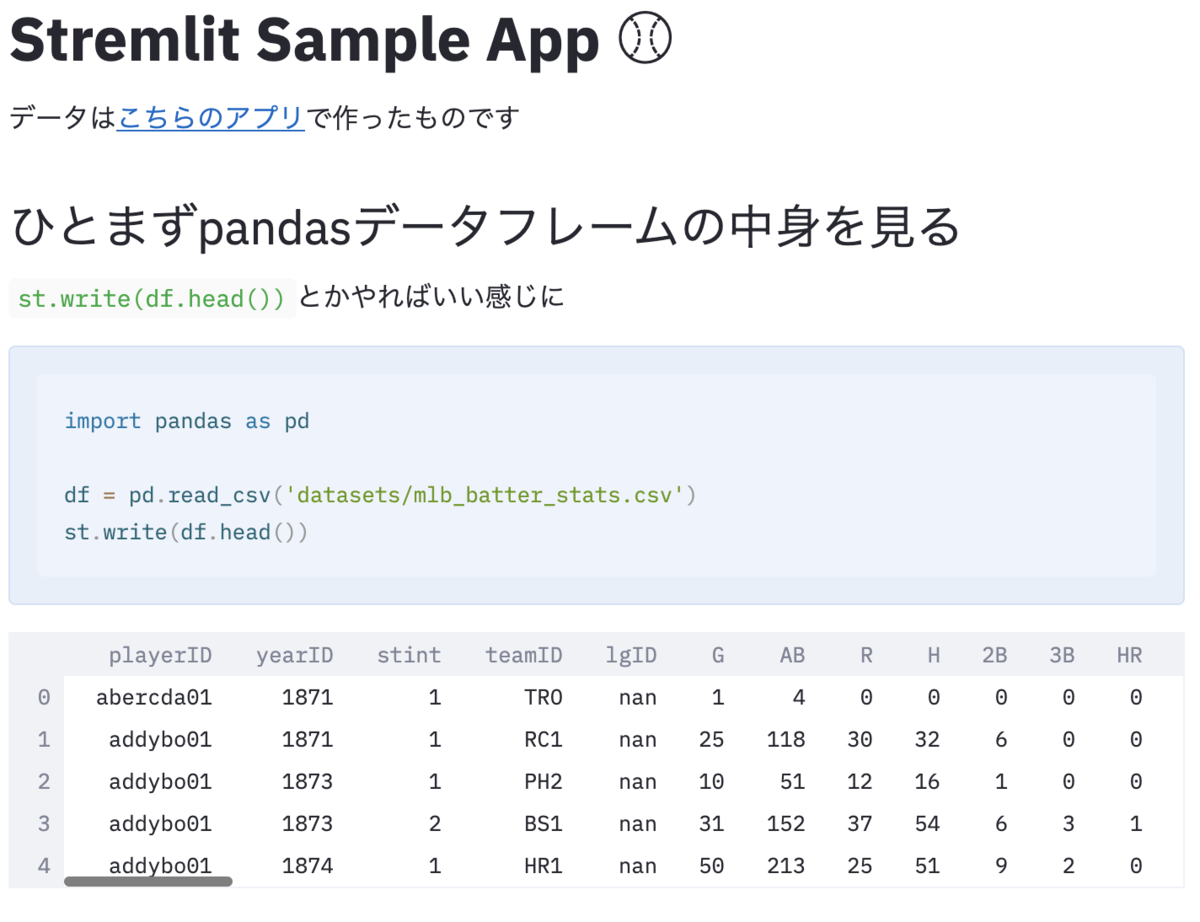
素の Emotion や類似の CSS in JS ライブラリでは、 1 つの TS/JS ファイル内に CSS を書くような感じでスタイル設定を行っていきます*1。CSS in JS ライブラリに概ね共通しているのが、 styled.タグ名 でスタイリングすることです。
const Title = styled.h1` font-weight: bold; font-size: 20px; ` const Entry = styled.div` line-height: 1.5; margin-top: 20px; ` type Props = { title: React.ReactNode } const Article: React.FC<Props> = ({ title, children }) => { return <> <Title>{title}</Title> <Entry>{children}</Entry> </> }
コンポーネント志向で作っていく上で、上記のコードには責務的な問題があります。 Entry は「上部の要素と 20px 空ける」というマージン指定をしていますが、「隣接要素との距離」は当該コンポーネントの責務外です。あくまで Entry を呼び出す側(親)が、どれくらいの間を開けるのが適切か知っているべきです。
Utility First な CSS in JS フレームワークを導入すると、次のように書くことができます。以下の例での「mt」という prop は、margin-top を指定するための prop です。
import { Title, Entry } from '~/components' const Article: React.FC<Props> = ({ title, children }) => { return <> <Title>{title}</Title> <Entry mt={4}>{children}</Entry> </> }
マージン、サイズ、色などのあらゆるスタイルが prop で渡せるような CSS in JS フレームワークを、本稿では「Utility First な CSS in JS フレームワーク」と呼称します。このようなフレームワークは、素の Emotion や styled-components を拡張するような形(一緒にインストールする)で作られています。
Utility First な CSS in JS フレームワークのメリット
上記の例は inline style (style prop にわたす形)でも実現できる例ですが、Utility First なフレームワークには次のようなメリットがあります*2。
- 型安全性が高い
- レスポンシブに対応している
- デザインシステムとの親和性が高い
- ホバー時などの挙動も指定できる
例えば、以下のコードは、上記のメリットを同時に満たしています。
import { x } from '@xstyled/emotion' const Box = (props) => { return <x.div // primary のような独自定義の色名が型安全に color="primary" // レスポンシブ指定 display={{ _: "block", md: "flex"}} // ○○px じゃなく、デザインシステムに則ったマージンパターンを指定 mt={4} // ホバー時の色指定 hoverColor="red" {...props} /> }
実際に書いてみるとわかるのですが、 TypeScript (JavaScript)の仕組みの上で動いているためコード補完が効きやすく、コード量も少なくスタイルが書けるので、生産性が高く感じられます。そのため、自分が関わるプロジェクトでは積極的に導入しています。
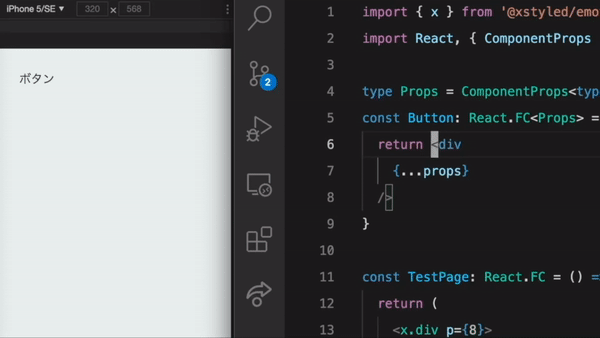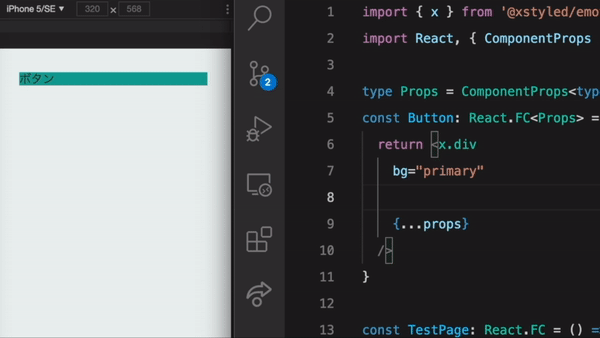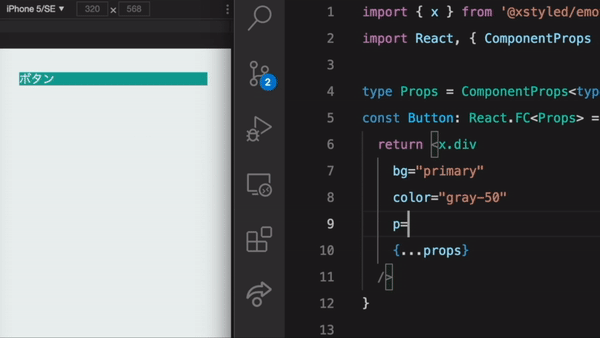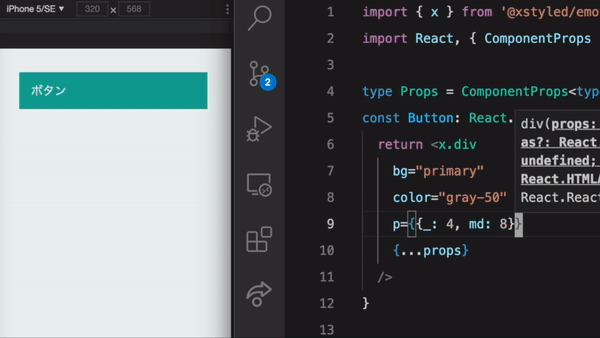
ここからは、このような特色を持った React 向けの CSS in JS フレームワークを3つ紹介していきます。いずれのフレームワークも、2019年ごろにリリースされ、アクティブに更新されています。特に最近は Chakra UI の人気が高いようです。2021 年 4 月現在の GitHub Stars をライブラリ名に併記しています。
Chakra UI (★16.6k)
Chakra UI は Utility First な CSS in JS フレームワークとしての機能と、(Material UI のような)リッチな既成コンポーネントが一緒になったライブラリです。 <Box> が基本的なユーティリティコンポーネントになっているので、これを使っていきます。<Flex> や <Grid> といったレイアウト用の Box も用意されています。
import { Box } from "@chakra-ui/react" const Entry = (props) => { return <Box // as で div 以外のタグを指定できる as="section" // レスポンシブは { base: 2, md: 3 } のような形だけでなく、array で指定できる m={[2, 3]} color="gray.600" {...props} />
xstyled (★1.6k)
xstyled も Chakra UI と同じようなユーティリティ prop が定義されていますが、CSS in JS フレームワークとしての機能に特化しています。xstyled は <x.タグ名> というコンポーネントが用意されていて、通常のタグでのコーディングと書き味が似ています。
import { x } from "@xstyled/emotion" const Entry = (props) => { return <x.section // レスポンシブ m={{ _: 2, md: 3 }} // color="primary" {...props} />
4月1日にリリースした、信濃毎日新聞様との参院長野補選特設ページ でも使っています。
Theme UI (★3.6k)
Theme UI も Chakra UI 同様、 CSS in JS フレームワークとしての機能と、一部既成コンポーネントが一緒になったライブラリです。Chakra UI に比べて、既成コンポーネントは少なく、また、prop で網羅的に CSS 指定できることを志向していません*3。そのため <Box> だけでなく sx という prop (style prop に類似)を併用して使います。
import { Box } from "@xstyled/emotion" const Entry = (props) => { return <Box m={[2, 3]} sx={{ // textAlign という prop は Box に存在しない textAlign: 'center' }} {...props} />
番外編1:Tailwind CSS
最近もっともよく聞く Utility First な CSS フレームワークは Tailwind CSS でしょう。Tailwind はスタイルをクラス名で指定していきます。Tailwind はそもそも CSS-in-JS のライブラリではないので、番外編としました。Chakra UI や xstyled と似たような機能が生えていますが、型安全な prop で渡すわけではありません。
const Box = (props) => { return <div className="mt-4 rounded text-blue-600 md:text-green-600" {...props} /> }
番外編2:自前で整える
本稿で紹介したようなライブラリを入れたくないという人もいると思います。これらのライブラリは emotion や styled-components の上に作られているフレームワークに過ぎないため、自前で整えていくことも可能です。
// mixins.ts type MarginProps = { m?: CSSProperties['margin'] } const marginMixin = ({ m }: MarginProps) => ({ margin: m, }) // Entry.tsx const Entry = styled.div<MarginProps>` ${marginMixin} line-height: 1.5; ` // Page.tsx const Page = () => { return ( <> <Title /> <Entry m={30} /> </> ) }
自前であれば軽量に始めやすいのですが、最初に紹介したようなメリット(レスポンシブ等)を網羅的に用意していくのが相当面倒くさいです。styled-system のようなライブラリもありますが、メンテされていません。*4
IE 対応
Internet Explorer のサポートを捨てられない、という場合もあると思います。対応状況を簡単にまとめたので、ぜひ参考にしてください。
| ライブラリ | 公式サポートの宣言 | 動作 | 補足 |
|---|---|---|---|
| Chakra UI | ✗ | ✗ | |
| xstyled | ✗ | ○ | ごく一部に CSS Variables が使われているので、それを避ければ可能*5 |
| Theme UI | △ | ○ | 公式サポートの記載はないが、CSS Variables を使わないための設定が明示されているcore-js/web/dom-collections のポリフィルが必要 |
| Tailwind | ✗ | 未調査 |
残念ながら、明確に公式サポートを謳っているライブラリはないのですが、 xstyled、Theme UI あたりは動作可能です。先ほど紹介した参院長野補選の特設サイト では IE 11 もサポートしていますが、概ね問題なく動いています。
IE で全く動かないものは、CSS Variables を使っているものです。CSS Variables の方がパフォーマンスはよさそうなので、ブラウザ互換性とパフォーマンスとのトレードオフになりそうです。
まとめ
本稿では、Utility FIrst な CSS in JS フレームワークを紹介しました。デザインシステムや TypeScript との親和性が高く、生産性高くコーディングできるので、ぜひ利用を検討してみてください。
また、JX 通信社ではフロントエンドに限らずインターン生を通年で募集しています。フルリモートでも働けます。
*1:エディタのプラグインを入れると、スタイル部は CSS のようにハイライトされます
*2:xstyled の説明を元に加筆しています
*3:下位互換というよりは、思想の違いだと思います
*4:styled-system の作者が Theme UI を開発メンバーの一人です
*5:ソースコードを var で検索するとでてきますが、Flex 向け spacing や transform などです。色、サイズ、マージンなどの基本機能は問題なく動きます。