こんにちは!私はファンヨンテと申します!JX通信社で機械学習エンジニアを行っております!
私はPyTorch Lightningを初めて使ったときの便利さに感動した以来、PyTorch Lightningのヘビーユーザーです!
この解説記事ベビーユーザーの私が皆様にPyTorch Lightningを知っていただき、利用のきっかけになってほしいと思って公開しています!
今回の解説記事のサンプルコードはこちらにあります。ぜひ、実際のコードを手にとって体験しPyTorch Lightningの素晴らしさに触れてみてください!
この記事内容は13回のMLOps勉強会で発表しました!
speakerdeck.com
読者の対象
- PyTorch Lightningを使ってみたいが、最初の初め方がわからない人
- PyTorch をある程度知っている方
PyTorch Vs PyTorch Lightning
PyTorch について
PyTorchはDeep Learningを実行する時に用いられる代表的なフレームワークですが、自由度が高く、個々人で自由な記述が可能です。これはメリットでもありますが、可読性が非常に低くなるリスクがあります。また、学習時のモデルや結果の保存など、サイエンスの側面とは異なるコード書くタイミングが多く、コーディングに多くの時間を取られます。したがって、PyTorchで機械学習を行うなら、データサイエンティストにはサイエンスの能力とコーディングの2つの能力が求められます。 図1 PyTorchを用いた時に、MLエンジニアが行う業務
図1 PyTorchを用いた時に、MLエンジニアが行う業務
PyTorch Lightningについて
一方、データサイエンティストが力を存分に発揮し、これまで想像されなかった革新的なことをしたいなら、コーディングの部分よりサイエンスの領域に力を注ぐべきだと思います。
PyTorch Lightningを用いると、コーディングにかける時間を最小限にし、データサイエンティストがサイエンスの領域に全力を捧げられるようになります。
 図2 PyTorch Lightningを用いるとサイエンスの部分に注力できる
図2 PyTorch Lightningを用いるとサイエンスの部分に注力できる
JX通信社でPyTorch Lightningを採用した理由
JX通信社のMLチームでは"力を使うべき場所に注力しよう"ということを理念を大事にしており、その工夫の一つとして学習・デプロイのテンプレートコードを作成し、運用しています。そのテンプレートはPyTorch Lightningをベースに記述されています。詳しくはこちらのブログをご参照ください。
PyTorch Lightningとは
PyTorch Lightningは"データサイエンティストはサイエンスに力を捧ぐべきで、コーディングは最小限の労力で"をコンセプトに作成された、PyTorch のラッパーです。PyTorch Lightningは後述するように、コードの書き方に指定があり、サイエンスに関わる部分(モデルのアーキテクチャ、学習方法、前処理の方法など)をメインに書きます。このコードの書き方の適度な矯正はチーム間での可読性を上げる効果もあります!また、GPU、TPUでの学習や、モデルと結果の保存など複雑なコーディンに関わる部分は数行書き足すだけで、実行することができるようになっています。
 図3PyTorch LightningのHPより引用
図3PyTorch LightningのHPより引用
PyTorch Lightningの柔軟性について
この様に聞くと、柔軟性が欠けており、できない実験があるのでは?と感じる方もいると思います。しかし、柔軟性を最大化することがPyTorch Lightningの哲学として紹介されており、ほとんどすべての実験を再現することが可能です。
 図4Lightning Design Philosophy Githubより引用
図4Lightning Design Philosophy Githubより引用
またPyTorch Lightningをずっと使ってきたの私個人的な意見としては、こちらのブログにも記述されている通り、業務においてPyTorch Lightningの記述で困ったことはほとんどなく、メリットのみを享受しています。(しかし、半教師あり学習をPyTorch Lightningで記述しようとした際、Optimizerの記述に沼ってしまい、余計な時間と労力を費やしたことが一度あります。)
PyTorch Lightning の書き方
サイエンスに関わる部分
PyTorch Lightningに書き方のフレームワークがあり、そこを埋めていくように書くと記述しました。このページでは、PyTorch Lightningの書き方を、PyTorch との差分という意識で記述させていただきます。このムービーは非常にわかりやすいムービーですので、こちらのムービーをご覧になっていただいてから、下の章を読んでみてください。
Google Colabで動作するサンプルコードはこちらにあります。ブログの内容と全てが一対一対応してませんが、実際ご自身の手で動かしてみてください!
PyTorch LightningはDataに関わる部分(DatasetやDataloader等)と学習に関わる部分(モデルの構造、学習ループの書き方)に大きく区分されます。
Dataに関する部分(LightningDataModule)
PyTorch では学習に用いるデータはtorch.utils.dataのDataLoaderやDatasetを用いて記述されます。PyTorch Ligthningでは、LightningDataModuleを継承したクラスを作成し、その中のtrain_dataloader()と名のついた関数にtrainに用いるDataloaderをreturnする必要があります。validation, testも同様です(図5)。ここで注意すべきなのは関数名は変更してはなりません。この様に関数名が完全に決まっているので、他のチームメンバーがコードを読むときにどのデータがどこに利用されているのかわかりやすくなります。
LightningDataModuleには、このページで紹介した関数以外にも多くの関数が定義されています。LightningDataModuleについての詳細は公式のドキュメントをご覧ください.
 図5LightningDataModuleについて
図5LightningDataModuleについて
学習に関する部分(LightningModule)
PyTorch では、torch.nnのmoduleを継承したクラスでモデルの構造を決定し、その後、学習ループをtrain.pyなどにベタがきすることが多いと思います。PyTorch Lightningでは、モデルの構造と学習ループでの計算挙動をLightningModuleで定義します。
図6はLightningModuleに必要な最低限のコードを示しています。まず、initでモデルのパーツを定義し、forwordでモデルの構造(計算の流れ)を定義します(ここまではPyTorchと同じ)。
次にPyTorch Lightningでは、学習ループの各ステップでどの様に計算してほしいかを記述します。図6では、training_step()という関数が定義されていますが、この関数は学習ループのミニバッチが与えられたときに、どの様に計算するのか記述してます。ここで、return のdict中の"loss"を鍵とする値を基にLightningの方で逆伝播や最適化が行われます。このときに用いられるOptimizerやschedulerはconfigure_optimizers()に定義する必要があります。
図6では、training_step(学習のミニバッチに対する処理)だけが書かれてますが、training_epoch_endやvalidation_step, validation_epoch_end, on_fit_startなど、学習ループの各ステップで行ってほしいことの記述が可能になっています。
また、PyTorchでは学習ループの記述の際、データやモデルをCPUやGPUに移動する必要があり、.to(device)が至る所に記述する必要があると思います。PyTorch Lightningを用いているとto(device)の記述しなくても、Lightningが自動で学習に用いるデバイスにデータを移動してくれます。LightningModuleについての他の関数を含む詳細はこちらを御覧ください。
 図6 LightningModuleについて
図6 LightningModuleについて
学習の初め方
上で定義した、LightningDataModuleとLightningModuleを用いて学習するには、Trainerを定義し、trainer.fitで学習されます(図7)。
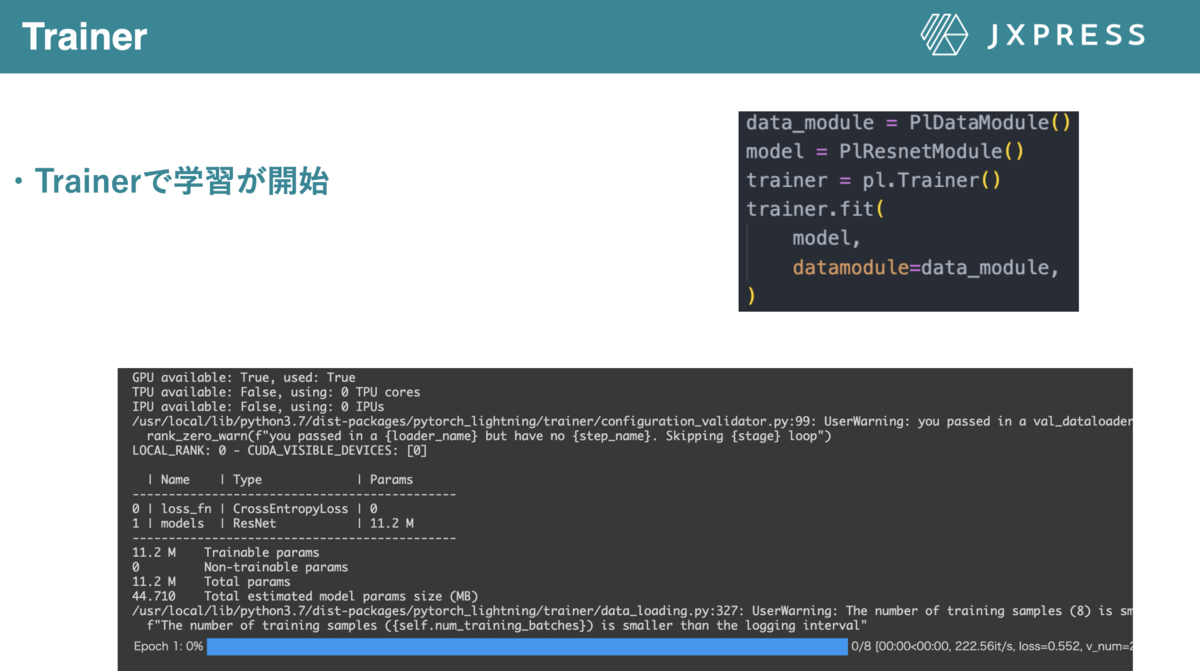 図7Trainerで学習が開始される。右の図は実際のコード下の図は学習が開始されたときのコンソールの表示
図7Trainerで学習が開始される。右の図は実際のコード下の図は学習が開始されたときのコンソールの表示
サイエンスに関わるコードの書き方まとめ
このページではサイエンスに関わるコードの記述法について記述してきました。PyTorch Lightningを利用していると、上記で解説したサイエンス部分の実装に費やす時間が多くなります!
一方、ここまで読まれた方は以下の疑問を思ったと思います。
- 結果の表示や保存はどうするの?
- モデルの保存方法は?
- 学習のデバイスをどの様に指定するのか?
こちらは、Lightningを用いていると、数行の追加で終了します。これがLighthningの強みだと思います。詳細は次章以降のページにて解説します!
サイエンス以外の部分のコードの書き方(結果の表示と保存について)
前章ではPytorch Lightningのサイエンスに関わる部分のコードの記述方について解説しました。
ここでは、結果の表示法と保存法について記述します。
前回の解説で、Lightningでは学習ループの段階ごとの計算挙動を記述すると記述しました。このときに見たい/保存したい結果があるとき、self.log()に見たいメトリクスを入れると、結果が記録されます (図8)。それぞれの引数の意味は以下のとおりです。
self.log(
"test_loss",
loss,
prog_bar=True,
logger=True,
on_epoch=True,
on_step=True,
)
 図8LightningModuleでのログの取り方について
図8LightningModuleでのログの取り方について
TorchMetricsの利用
TorchMetricsのライブラリを利用すると結果を非常に簡単に扱うことができます。TorchMetricsを用いることで、AccuracyやRecallなど一般的な指標が簡潔に書けるだけでなく、MetiricsCollectionを用いると複数の指標を一度に定義し(図9左)、計算することができます(図9右)。
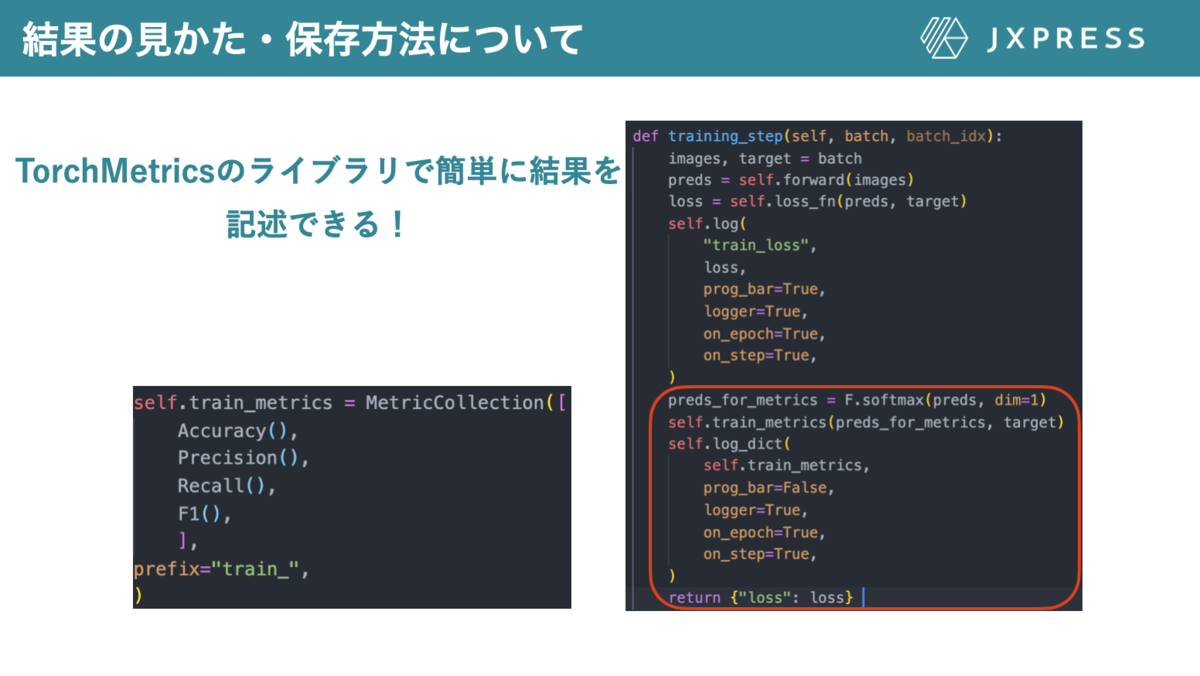 図9TorchMetricsに利用法
図9TorchMetricsに利用法
結果の表示
self.log()のprog_bar = Trueに設定したMetricsはプログレスバーに表示されます (図10)。
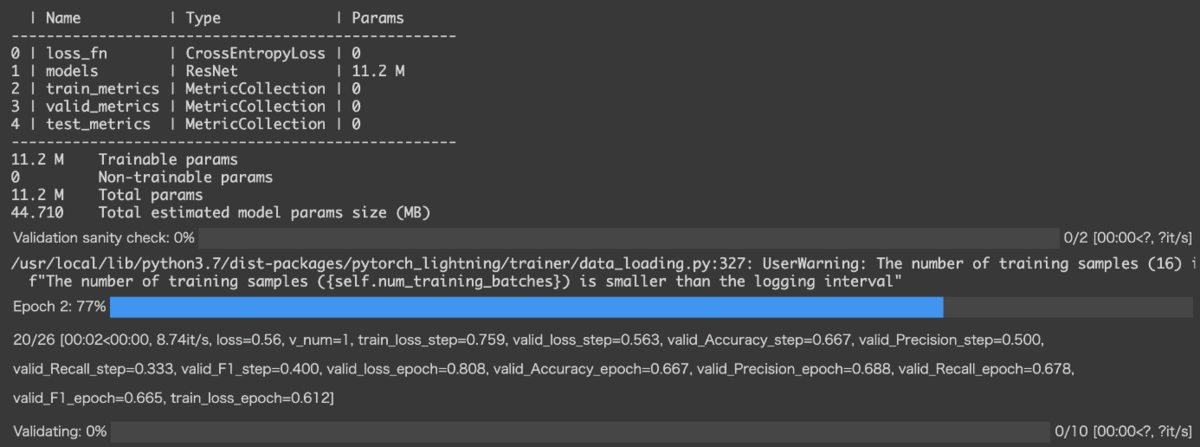 図10 self.logを入れたMetricsがプログレスバーの下に結果が表示される
図10 self.logを入れたMetricsがプログレスバーの下に結果が表示される
結果の保存方法
self.log()のlogger = TrueにしたMetricsの保存はどの様になるのでしょうか?
LightningのTrainerを定義するときにloggerを定義すると、その形式にあったログが自動で保存されます。このloggerにはTensorBoardだけでなく、MLFlow, Cometなど有名な実験管理ライブラリに対応していますので、自身の好きなライブラリを用いることができます。
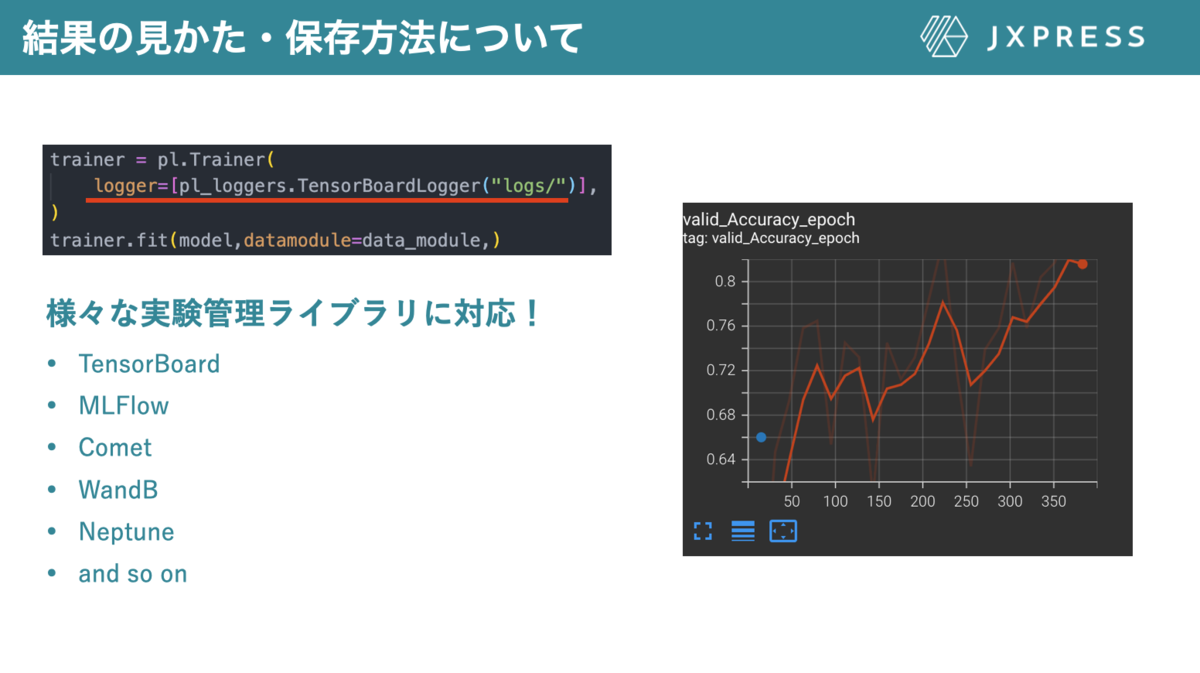 図11loggerについて。loggerにTensorBoardを定義すると(左上)、自動で結果がTensorBoardの形式で保存される(右)。
図11loggerについて。loggerにTensorBoardを定義すると(左上)、自動で結果がTensorBoardの形式で保存される(右)。
JX通信社ではGoogle App EngineにデプロイされたMLFlowに結果が保存される様にしています。詳細はこちらを御覧ください。
サイエンス以外の部分のコードの書き方(callback : モデルの保存とearly stopping)
前章は結果の表示と保存方法について解説しました。
このページではモデルの保存方法とEarly stoppingの方法について説明します。
そのためにはLightningのCallbackと呼ばれる機能について理解する必要があるため、先にcallbackについての解説を行った後にモデルの保存方法とEarly stoppingの方法について説明します。
callbackについて
PyTorch Lightning にはCallbackというmoduleがあります。Callbackを用いると、LightningModuleで定義した学習ループの計算挙動に新たな動作を差し込むことができます。
例として、図12の左の図の様に定義したcallbacksをtrainerに入れると、ミニバッチ学習が始めに"train_batch is starting"、終わりに"train_batch is completed"と表示されるようになります。
ですので、学習で普遍的に用いられる便利系のコードをcallbacksで定義しておくことで、LightningModule内の学習ループの定義は簡潔になります。
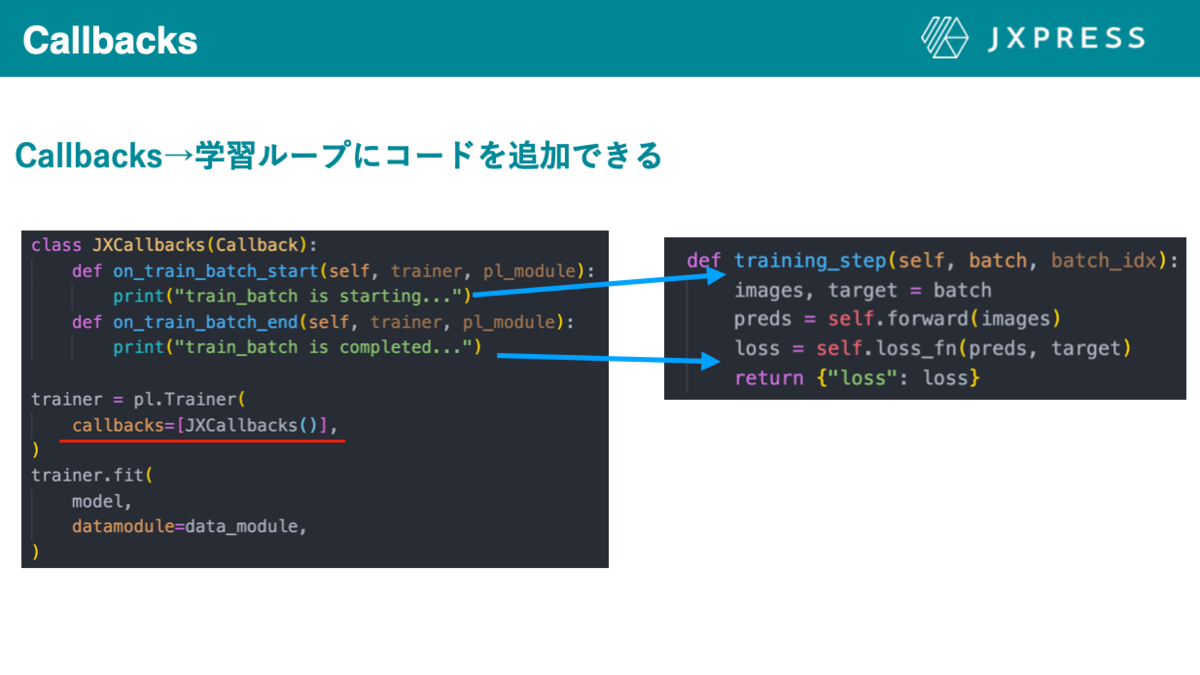 図12 callbackとは
図12 callbackとは
JX通信社でのcallbackの利用
JX通信社ではWebHookを通じて学習の進捗状況をSlackに知らせるcallbacksを作成し運用しています。詳しくはこちらを御覧ください!
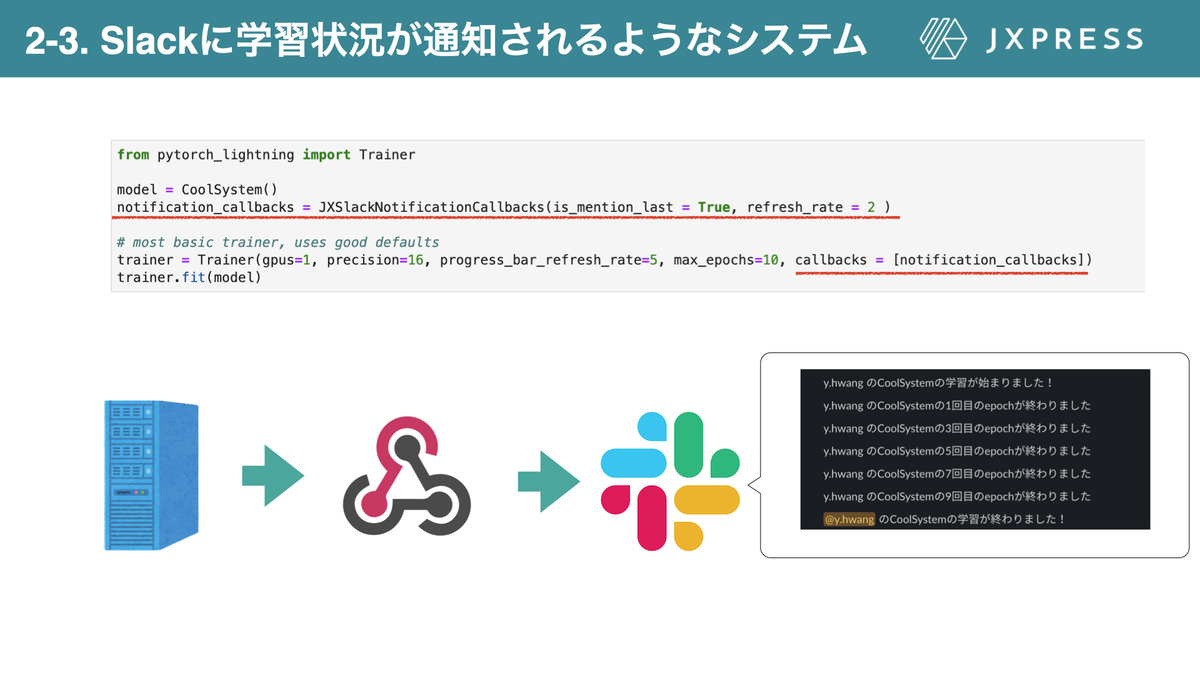 図13JX通信社でのcallbacksの利用。(https://tech.jxpress.net/entry/2021/10/27/160154より引用)
図13JX通信社でのcallbacksの利用。(https://tech.jxpress.net/entry/2021/10/27/160154より引用)
モデルの保存とearly stopping
Lightningから提供されるBuilt-in callbackを利用することもできます。
ここにはModelCheckpoint, EarlyStoppingなどの便利なcallbackがあります。
ModelCheckpointは指定した指標が最も高い/低いモデルを保存することができるcallbackです。このcallbackの素晴らしいポイントは監視対象を選択し、その値が最大/ 最小のときのモデルを保存するといったベストモデルを保存することができます(図3の場合、valid_lossが最小になるモデルが保存される)。
EarlyStoppingは文字通りearly stoppingのためのcallbackであり、監視対象の値が改良しない場合、学習がストップしてくれます。この2つのcallbacksをTrainerの引数に入れ込むだけで、モデルの保存とearly stoppingを簡単に実装することが可能になります。
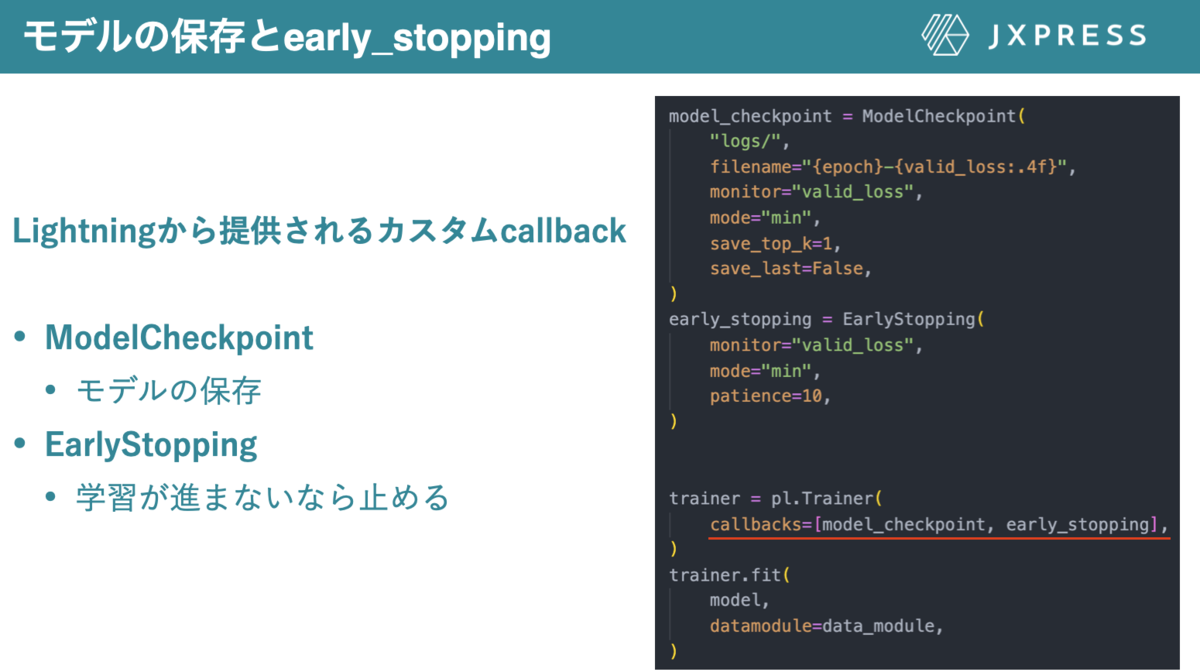 図14Lightningが提供するカスタムBuilt in callback(ModelCheckpoint, EarlyStopping)
図14Lightningが提供するカスタムBuilt in callback(ModelCheckpoint, EarlyStopping)
その他、Built in callbackについては公式のドキュメントをご覧ください。
サイエンス以外の部分のコードの書き方(GPU /TPU /IPUでの学習)
GPU, TPUで学習速度を上げる
Deep learningのモデルはcpuで学習させるには非常に時間がかかります。一方GPU, TPUを用いると、学習期間が数倍~数十倍程度加速されるため、GPU, TPUで学習することが一般的だと考えられます (図15)。
一方PyTorchを用いてGPU, TPUで学習させることを考えると、至る所に.to(divice)を書く必要があり、可読性が下がるだけでなく、不必要なエラーが発生する原因になります。
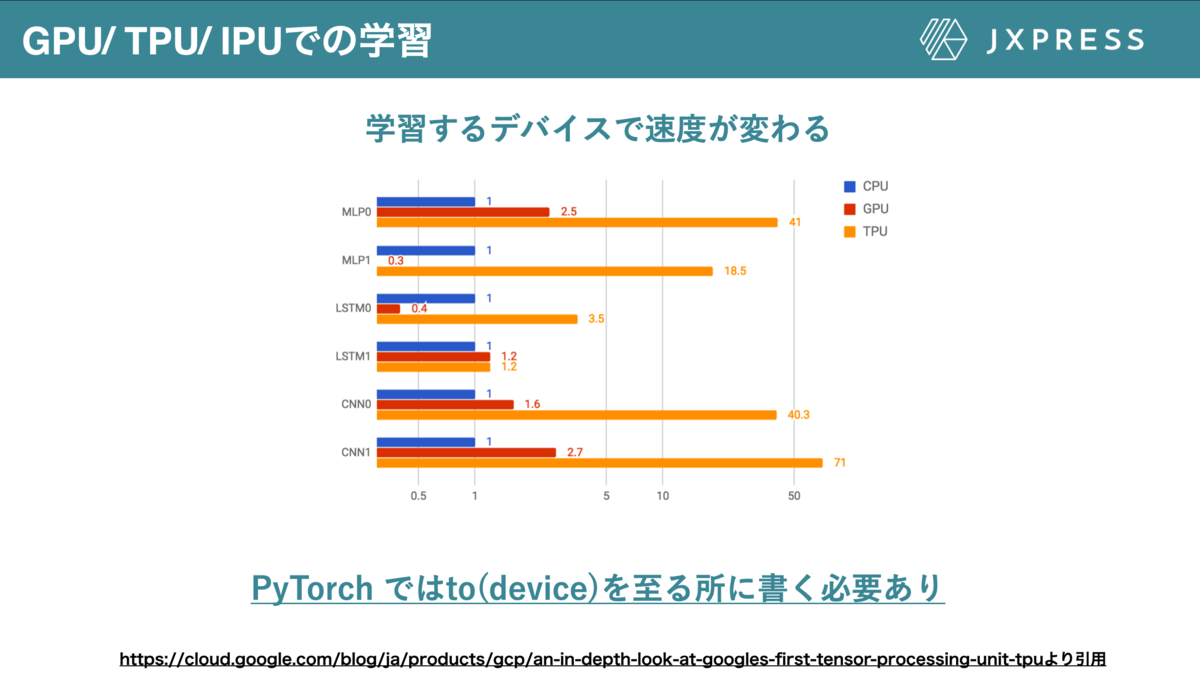 図15GPU, TPUの利用は学習速度を加速させる。このブログより引用
図15GPU, TPUの利用は学習速度を加速させる。このブログより引用
LightningでのGPU, TPUで利用法
LightningModuleではto(device)のコードを一切書くことなく学習ループを実装します。では、Lightningではどの様にGPU/TPU/IPUで学習することができるのでしょうか?
答えは非常に簡単で、Trainerのgpus/tpu_cores/ipusで利用するGPU/TPU/IPUを指定すると指定したデバイスで学習が開始されます (図16)。
ここで、例えば、gpusの引数にlist型を入れると、学習に用いるGPUのデバイスを詳細に指定することができます。一つの要素しか無いlistを入れるとGPU1台での学習になりますが、複数の要素のlistを入れる、または2以上のintを入れると複数GPUでの並列学習が可能になります。より詳細は公式のドキュメントを御覧ください。
 図16学習するデバイスを変更するためにはTrainerの引数を指定するだけで良い
図16学習するデバイスを変更するためにはTrainerの引数を指定するだけで良い
ColabでのTPU利用について
google colabでTPUの利用したい場合は、以下のコマンドを打ってxlaをインストールする必要があります。
!pip install cloud-tpu-client==0.10 https://storage.googleapis.com/tpu-pytorch/wheels/torch_xla-1.9-cp37-cp37m-linux_x86_64.whl
(ここで、torch_xla-1.9の1.9は利用しているTorch のVersionを指定してください)
その後Tranerのtpu_coresの引数を指定することで、TPUでの学習が開始されます。
PyTorch Lightningより上位のラッパー (PyTorch Lightning Flash)
これまで紹介してきたとおりPyTorch LightningはPyTorchのラッパーでコーディングにかける時間を最小限にし、サイエンスにかける時間を最大化してくれました。
ここではPyTorch Lightningのより高位ラッパーであるPyTorch Lightning Flashについてご紹介させていただきます!
PyTorch Lightning Flashは高レベルのAIフレームワークであり、このライブラリを用いることで、図17のような典型的なタスクであれば、十数行のコードで解決することができます。また、PyTorch Lightningのラッパーであるため、Pytorch Lightningで利用できた機能(callbackや, loggingなど)をそのまま利用することができます。
サンプルコードの前半にPyTorch Lightningで行った画像分類タスクを後半のPyTorch Lightning Flashで実装しています!興味がある方はこちらも触ってみてください。
Lightning Flashができるタスクについてはこちらを御覧ください。 図17Lightning Flashから引用
図17Lightning Flashから引用
PyTorch Lightning Flashの個人的な利用方法
PyTorch Lightning Flashは数行のコードで機械学習タスクが完結する反面、柔軟性に乏しく、タスク目的に合わせた工夫が困難です。
したがって、個人的にはPyTorch Lightning Flashでベースラインを構築し、精度が十分ならそのまま利用します。一方、タスクに合わせた工夫が求められたときにはPyTorch Lightningのテンプレートコードを基に実験を行います。PyTorchの利用は最終手段だと思っていて、Lightning単体で実装できない最先端の工夫をしたい時に利用すると思います!
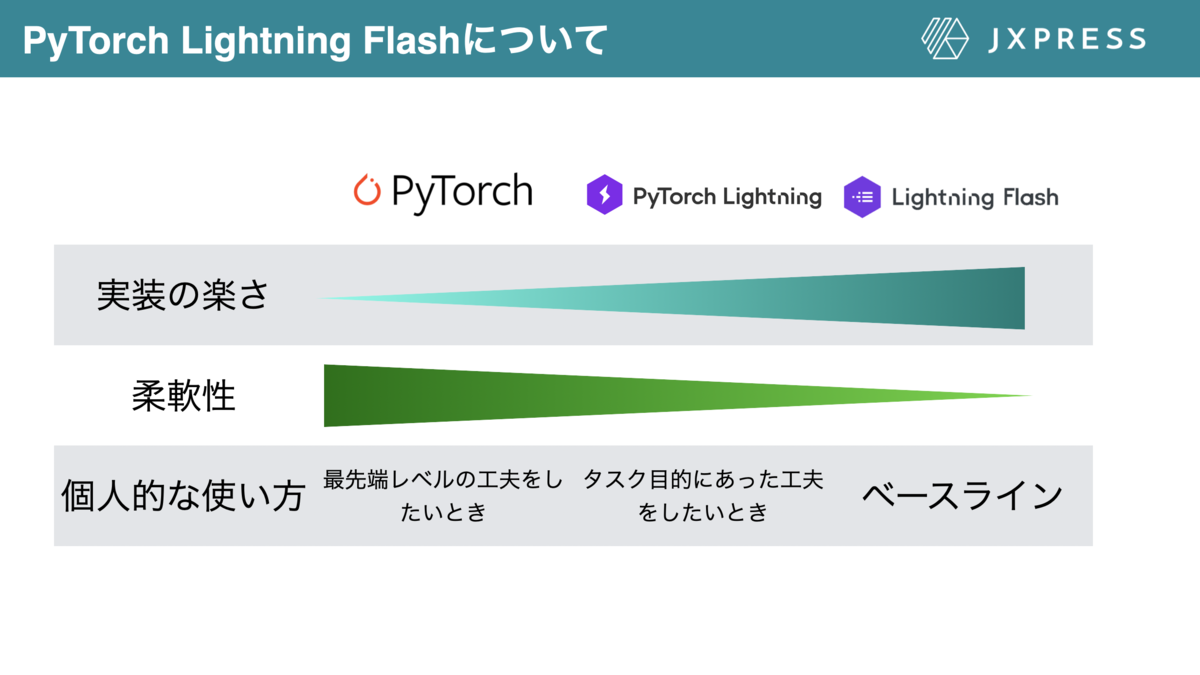 図18 Pytorch のラッパーの個人的な利用方法
図18 Pytorch のラッパーの個人的な利用方法
我々とともに挑戦する仲間を求めています
我々とともに成長しながら、より良い社会のためのMLを開発したい仲間を社員・インターン問わず積極的に募集しています!また、MLエンジニアはもちろん、あらゆる職種のエンジニアを求めています!
正社員、インターン、おためし入社などなど!ほんの少しでも興味を持たれた方はこちらを覗いてみてください!
日本でPyTorch Lightningを盛り上げていきたい!
個人的に、日本でPyTorch Lightningを盛り上げていきたい!と思っています。
PyTorch Lightningをこれまで使っていた方、これから使いたいと思っている方、質問がある方!積極的に私のtwitter, またはFacebookにご連絡ください!