こんにちは、CTOの小笠原(@yamitzky)です。
最近、LLMを使ってブラウザ操作を自動化する、browser-use が流行っていますね! 今回は、毎月実施している情シスタスクの一つをテーマに、browser-use で業務自動化できるかを検証してみました。
browser-use とは
browser-use は、AIエージェントを使ってブラウザ操作を自動化するツールです。ブラウザ操作には内部的には playwright を使い、AI 部分は langchain を使っています。また、タスクを遂行するためのエージェントとしての仕組み(タスクを分解して、ネクストアクションを決め、ゴールが達成できているかを評価する)も備わっています。
そのため、ざっくりと「◯◯◯のサイトを開いて、◯◯◯の予約をして」というと、ブラウザを動かしてゴールを達成してくれます。
ただし、「業務を自動化する」となるといくつかハイコンテキストな部分があり、雑に指示するだけでは難しいな、という印象です。
自動化したい情シスタスクの概要
情シス部門では毎月、「アカウントの棚卸し」という業務を行っています。これは、各種SaaSサービスにログインし、アカウント一覧をCSVなどでエクスポートし、退職済みの方がいないか、使われていないライセンスがないか、などを確認する業務です。セキュリティインシデントの防止や、コスト削減のために、単純ではあるものの重要な業務です。これを解決する SaaS などもありますが、それほど時間がかかっていないというのもあり、現在は手動で行っています。
今回は、Zoomを対象に「アカウント一覧をCSVなどでエクスポート」までを自動化してみます。
Step 1:公式ドキュメントに従って browser-use を使ってみる
import asyncio from browser_use import Agent, Controller from browser_use.browser.browser import Browser, BrowserConfig from langchain_openai import ChatOpenAI browser = Browser( config=BrowserConfig( headless=False, disable_security=False, ) ) controller = Controller() model = ChatOpenAI(model="gpt-4o") async def main(): task = "Zoom のユーザー一覧ページを開き、エクスポート → テーブル内のすべてのユーザー からダウンロードをしてください" agent = Agent( task=task, llm=model, use_vision=True, controller=controller, browser=browser ) await agent.run() await browser.close() if __name__ == "__main__": asyncio.run(main())
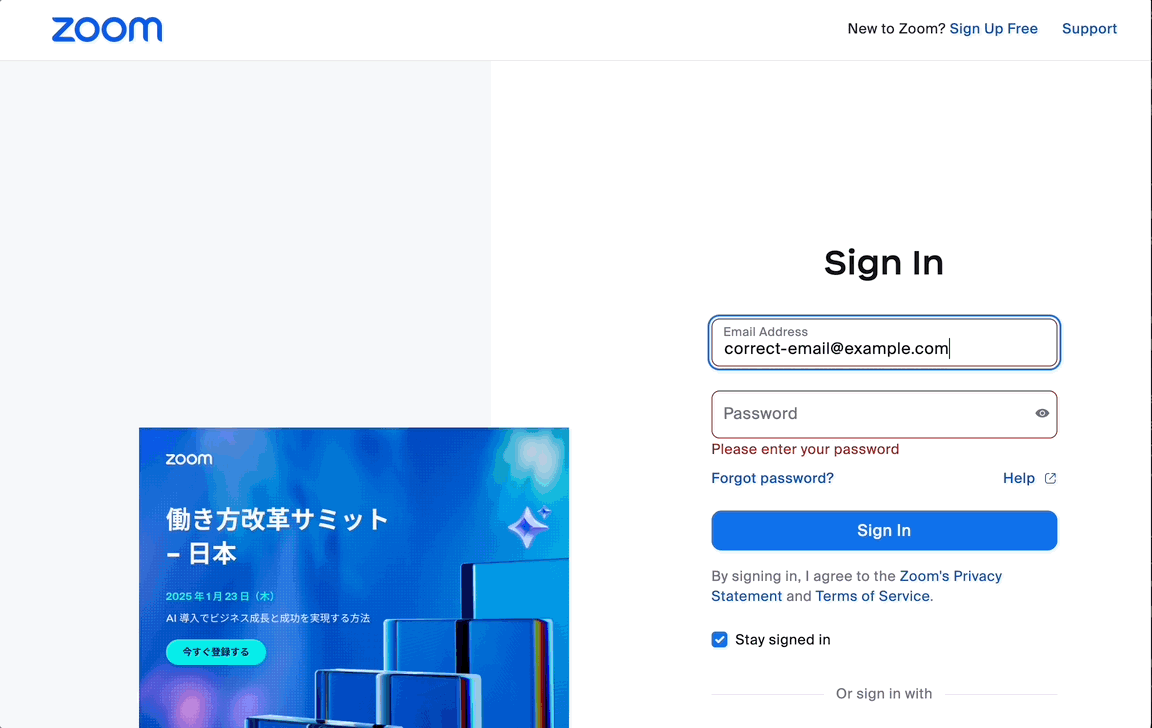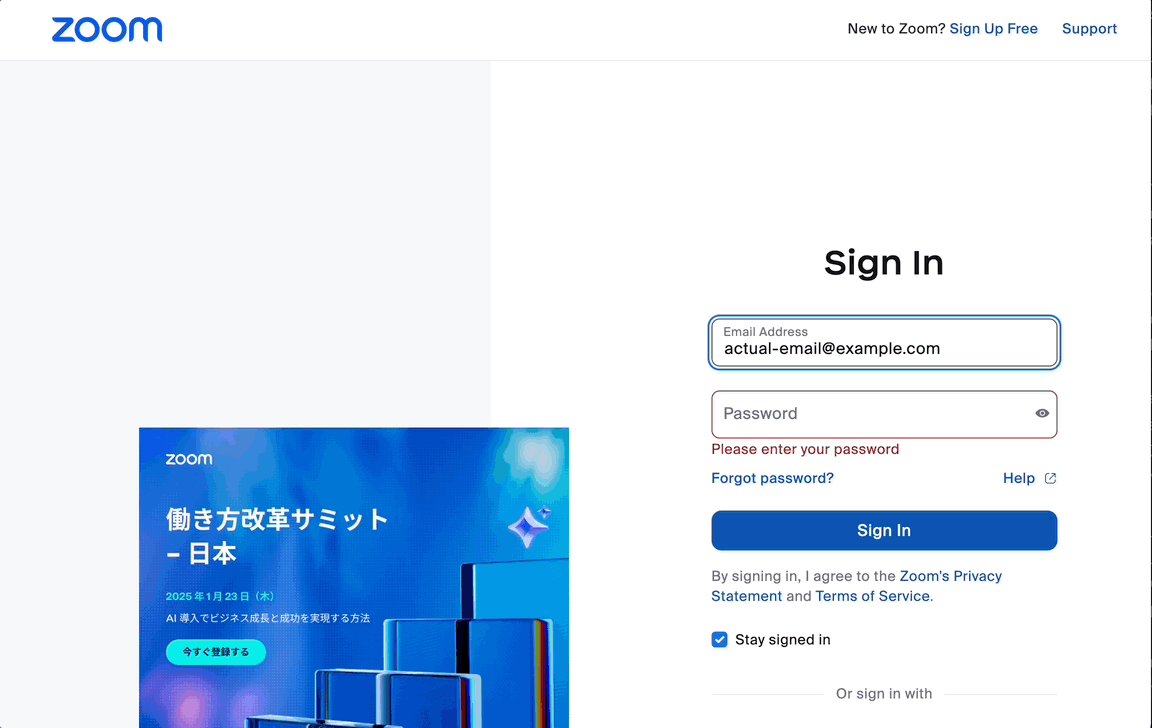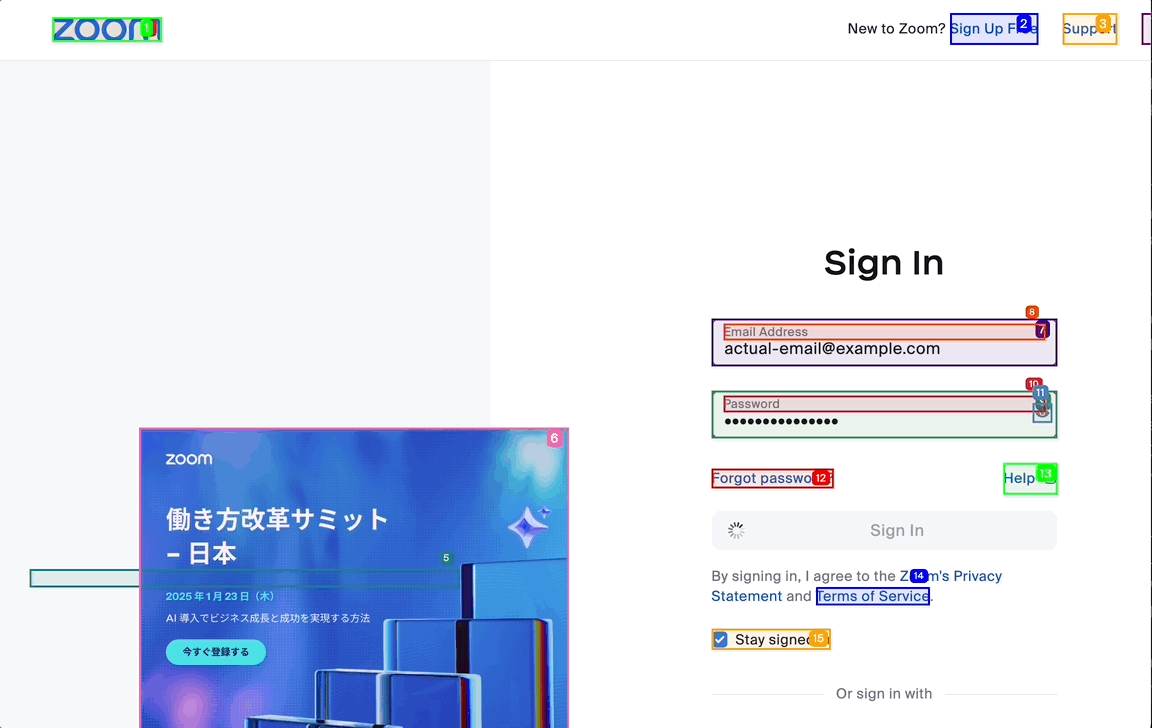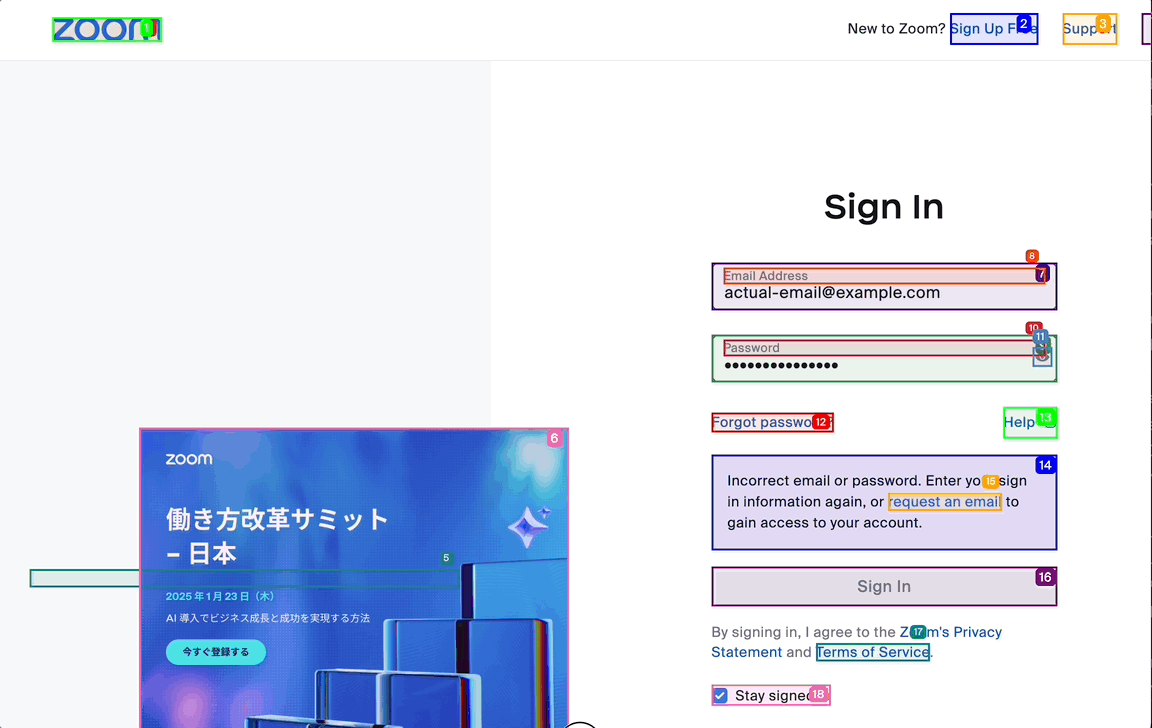
公式ドキュメントに従えば、上記のようなコードで動きそう... ですが、実際にはうまくいきません。業務知識として「ZoomのID/PASSWORD」が必要なので、エージェントにはログインできないのです。放置していると、下記スクリーンショットのように、存在しないアカウントでログインを試みます。
Step 2:ログインを実装する
さすがに LLM の API に ID/PASSWORD を送りたくないので、人間がログインをするようにしましょう。また、具体的にどの URL を開くのか指定した方が、結果が安定します。
# ...略... browser = Browser( config=BrowserConfig( chrome_instance_path="/Applications/Google Chrome Canary.app/Contents/MacOS/Google Chrome Canary", ) ) # ...略... @controller.action("ユーザーにログインを依頼する") def ask_login(): # Macユーザー限定 subprocess.run(["say", "-v", "Kyoko", "ログインしてください"]) input("ログインしてください。ログインが完了したら、Enterキーを押してください") return ActionResult( extracted_content="ログインが完了しました", include_in_memory=True ) async def main(): async with await browser.new_context() as context: task = "https://zoom.us/profile を開き、ログイン済みかを確かめてください。ログインが完了していない場合は、ユーザーにログインを依頼(ask_login)してください。" agent = Agent( task=task, llm=model, use_vision=True, controller=controller, browser_context=context, ) await agent.run() task = "https://zoom.us/account/user#/ を開き、エクスポート → テーブル内のすべてのユーザー からダウンロードをしてください" agent = Agent( task=task, llm=model, use_vision=True, controller=controller, browser_context=context, ) await agent.run() await browser.close()
一部を省略しましたが、 @controller.action("ユーザーにログインを依頼する") で tool を登録してあげると、人間に操作を依頼できるようになります。tool 名はプロンプト内で具体的に指定した方が、期待通りに動作をしてくれます。
加えて、次の3つのテクニックを追加しました。こちらは必須というよりは好みの問題です。
- 複数の Agent に分割している
- AI になるべく単純なタスクを与えるため。実際には、単一のAgent、単一のプロンプトでもうまくいくことが多いです。
- Playwright の Headless Chrome ではなく、実際のブラウザを使う(上記例ではChrome Canaryを指定)
- ログイン情報(セッション)が保存されたり、Chrome 拡張をインストールしておくことがやりやすいです。
- say コマンドで音声を読み上げる(Macユーザー限定)
- バックグラウンドで AI に操作させておいて、人間の対応が必要なときに気づけるようになります。
上記の対応で、ログインまではうまくいくようになります...が、実際にはエクスポートしたファイルのダウンロードができていません。
Step3:ダウンロードに対応
Step2では一見するとダウンロードが成功したように見えるのですが、Playwright の仕様でダウンロード済みのファイルにアクセスすることができません。関連した Issue も立っており、回避策が提案されています。
https://github.com/browser-use/browser-use/issues/91
事前に download イベントに対応する処理を記載する必要があります。
# ...略... def get_or_create_download_dir() -> Path: exe_dir = Path(os.path.dirname(os.path.abspath(__file__))) download_dir = exe_dir / "downloads" download_dir.mkdir(exist_ok=True, parents=True) return download_dir async def handle_download(download: Download): original_path = await download.path() # ファイル名からダウンロード元サイトがわかるよう、example_com 形式でドメインを追加 domain_prefix = download.url.split("/")[2].replace(".", "_") new_filename = f"{domain_prefix}_{download.suggested_filename}" new_path = get_or_create_download_dir() / new_filename os.rename(original_path, new_path) async def handle_new_page(page: PlaywrightPage): page.on("download", handle_download) async def setup_download(playwright_browser: PlaywrightBrowser): while len(playwright_browser.contexts) < 1: await asyncio.sleep(1) print("waiting for contexts to be created") for context in playwright_browser.contexts: context.on("page", handle_new_page) for page in context.pages: page.on("download", handle_download) async def main(): async with await browser.new_context() as context: pw_browser = await context.browser.get_playwright_browser() asyncio.create_task(setup_download(pw_browser)) # ...略...
これで、基本的には問題なく動くと思います!
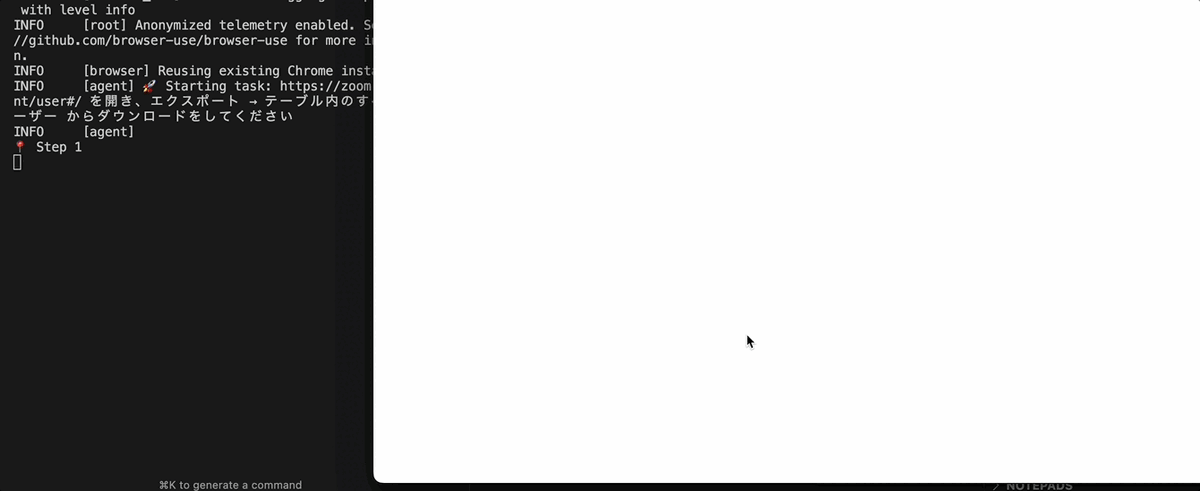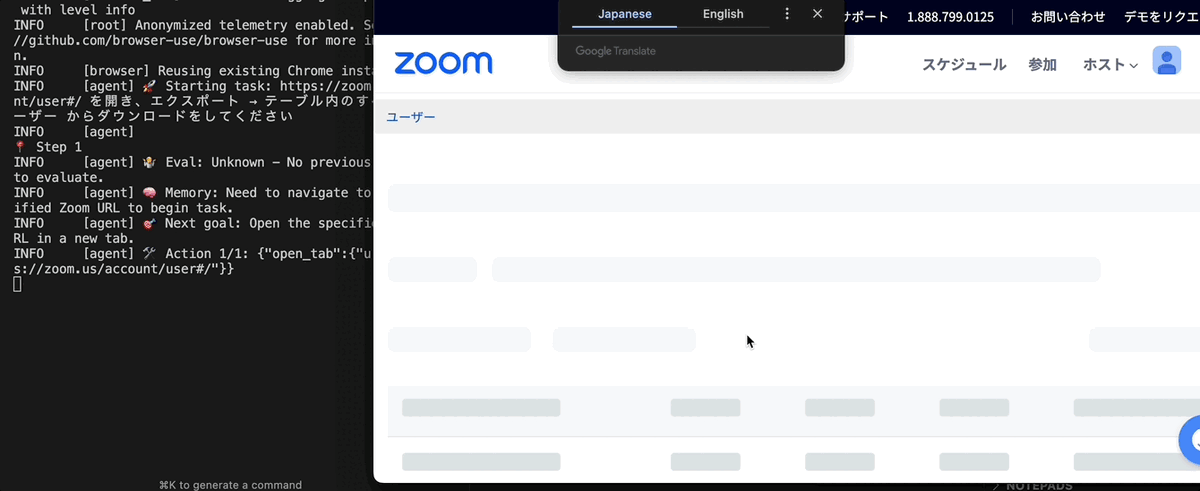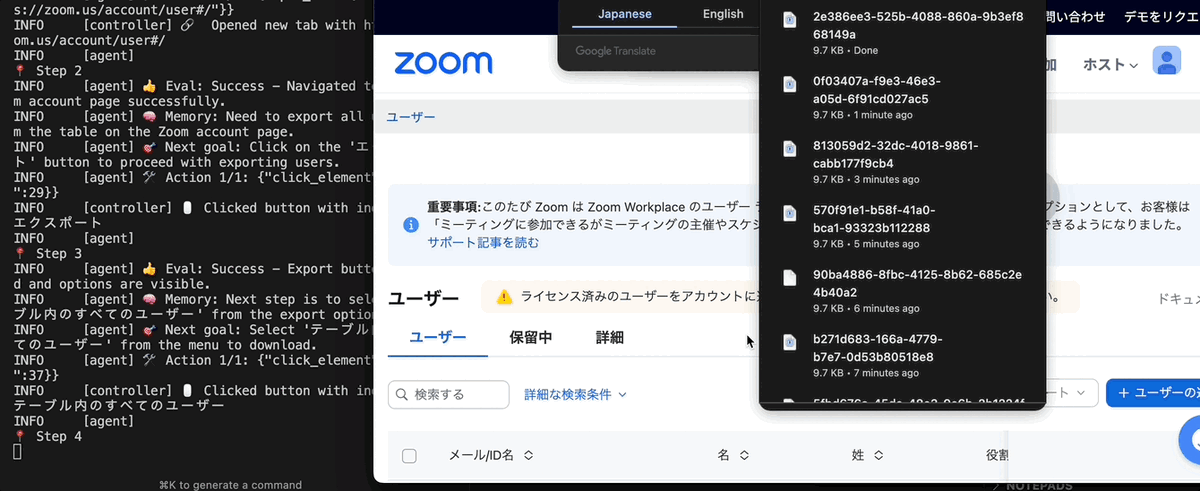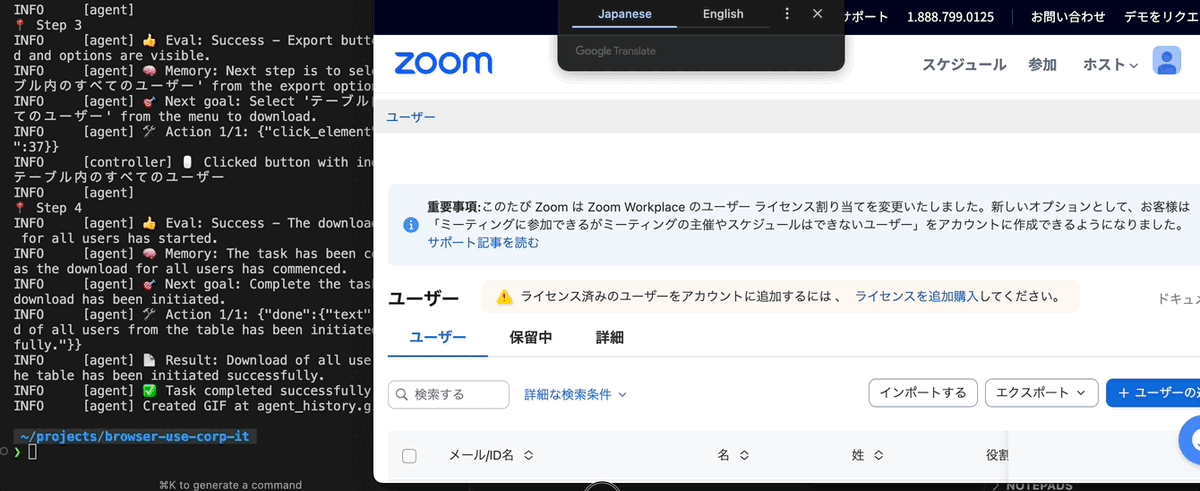
Step4:AI に処理の完了をちゃんと確認させる(おまけ)
今回の Zoom のエクスポートはかなり単純な例でした。他の SaaS では、エクスポートが非同期で行われることも多いです。複雑な処理の場合、Agent は誤って「ダウンロードが完了した」と誤解してしまうことがあります。
そこで、Agent にダウンロード済みファイルの確認をさせます。
# ...略... @controller.action("ダウンロード済みファイル一覧を確認する") def get_downloaded_files(): download_dir = get_or_create_download_dir() files = list(download_dir.glob("*")) if not files: return ActionResult( extracted_content="ダウンロードフォルダに現在ファイルはありません。", include_in_memory=True, ) file_list = "\n".join([f"- {file.name}" for file in files]) return ActionResult( extracted_content=f"ダウンロードフォルダの内容:\n{file_list}", include_in_memory=True, ) async def main(): async with await browser.new_context() as context: pw_browser = await context.browser.get_playwright_browser() asyncio.create_task(setup_download(pw_browser)) task = "https://zoom.us/profile を開き、ログイン済みかを確かめてください。ログインが完了していない場合は、ユーザーにログインを依頼(ask_login)してください。" agent = Agent( task=task, llm=model, use_vision=True, controller=controller, browser_context=context, ) await agent.run() task = "https://zoom.us/account/user#/ を開き、エクスポート → テーブル内のすべてのユーザー からダウンロードをしてください。作業を完了する前に、ダウンロードフォルダのファイル一覧(get_downloaded_files)を確認し、ダウンロードができているかを確認してください。ファイル名にはダウンロード元サイトのドメインが含まれています。" agent = Agent( task=task, llm=model, use_vision=True, controller=controller, browser_context=context, ) await agent.run() # ...略...
「ダウンロード済みファイル一覧を確認する」という tool を作成し、それによって作業の完了を確認させるようにしました。
実際、意地悪をして get_downloaded_files 関数が常に「ダウンロードフォルダに現在ファイルはありません。」を返すようにすると、延々とダウンロード処理を繰り返します。
振り返り
今回は「Zoom のユーザー一覧をエクスポートする」という作業をテーマに、browser-use での自動化をしてみました。
実際には他にも情シス業務の自動化を検証してみていますが、ハードルはやや高いかなという印象です。例えば、Google Sheets (スプレッドシート) のような複雑な UI の操作はあまりうまくいかない印象で、tool を用意してあげたり、タスクを分解してあげる、人間のレビューを挟むなど、「AI に期待しすぎない」というのがコツかなと思いました。
一方で、「AIでもわかるようにドキュメントや手順を簡略化する」という検討も進むので、良い機会にはなりました!
ぜひ皆さんも業務自動化をチャレンジしてみてください!