こんにちは。JX通信社 サーバーサイドエンジニアの内山です。
私が所属するNewsDigestチームでは先日、モバイルアプリ用APIをAWSからGCPにお引越しする、というプロジェクトを行いました。
会社の方針としてGCP利用を推進していることや、GCP特有のマネージドサービスの活用を視野に入れ、移行を決めました。
今回のAPI移行では、大きく以下2パートの作業がありました。
- APIのホスティングサービスをGCP上のものにするためのCI/CD設定, 定義作成, アプリケーション修正などの作業
- APIドメインのルーティング先をAWS -> GCPに切り替えるインフラ作業
本記事では、後者のルーティングに関して取り上げていきます。
作業概要・前提
今回は以下の制約を設けての移行としました。
- APIのドメインを変更しない
- ダウンタイムなしで行う
アプリ側には手を入れず、サーバーサイドチームで日中に完結させられるように・・と言う願いを込めた作戦です。
今回のメインテーマは、以下の点をケアすることです。
- 移行後の環境で最初からSSL証明書が有効な状態にする必要がある
- 何か問題が起こった場合に速やかに切り戻せる必要がある
- 移行を段階的に行なえると良い
これらについて、それぞれどのように対応したかを解説していきます。
有効なSSL証明書を事前に用意するには
選定理由などは省略しますが、今回のインフラ環境はCloud Load Balancing(以降CLB)を最前段に置いてバックエンドサービスにルーティングするという構成となっております。
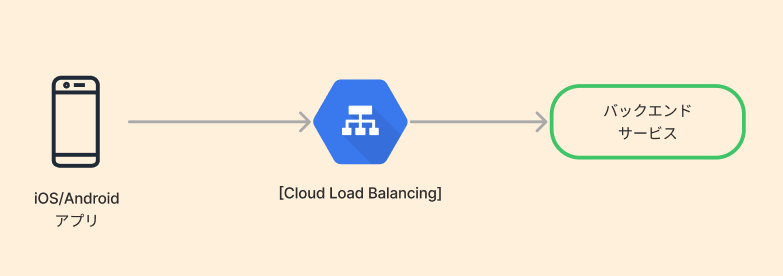
CLBでは、HTTPSプロトコルのフロントエンドサービス定義を作成する際に、GCP環境に用意しておいた証明書を紐づけることで設定を行います。
なお、Cloud Load Balancingに紐付けられるSSL証明書は以下の二種類があります。
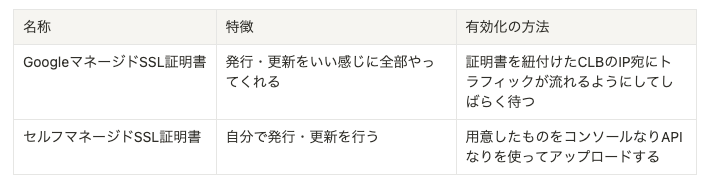
有効な証明書がない状態でリクエストを受けるとSSLエラーが発生してしまうので、GoogleマネージドSSL証明書の有効化のために稼働中のAPIのリクエストを向けるとなると、一時的なダウンタイムを許容するかメンテナンス中に行う必要があります。
一方、セルフマネージドSSL証明書は向き先変更前に有効な証明書を得ることができますが、証明書更新の手間が永続的に発生することとなります。
両者のいいところどりをしたい・・ダウンタイム許容したくないし運用もしたくない・・ということで、今回は以下の作戦を取ることにしました。
- セルフマネージドSSL証明書を紐付けた状態で向き先変更を行う
- その裏でGoogleマネージドSSL証明書を紐付けて有効化を行う
- GoogleマネージドSSL証明書が有効になったらセルフマネージド証明書をCLBから取り除く
結論、この手順で問題なく作業が行えました。GCPコンソールを利用する場合はほとんどぽちぽちで済むのですが、セルフマネージドSSL証明書の発行は手作業なため、再度行う際の備忘を兼ねて以下に手順を記載します。
セルフマネージドSSL証明書の発行・検証作業
セルフマネージドSSL証明書に関してはさまざまな発行・有効化の手法がありますが、今回はLet’s Encrypt証明書のTXT検証手順を採用しました。また、Let’s Encrypt証明書の発行手段として、今回はCertbotを利用することとしました。
詳細は省き、作成時の作業手順を紹介します。ドメイン名やメールアドレスは適宜書き換えて参考にしてください。
1: 以下コマンドで指定ドメインのTXTレコードに設定する文字列を取得
sudo certbot certonly --manual --domain api.example.com --email hoge@example.com --agree-tos --manual-public-ip-logging-ok --preferred-challenges dns
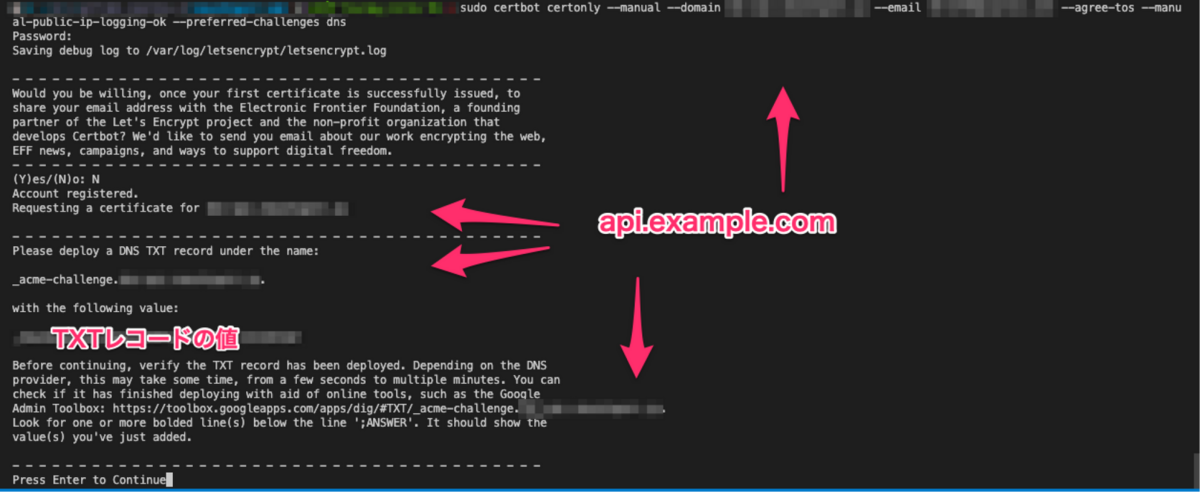
2: 該当ドメインのTXTレコードを作成

3: しばし待ち、手順1の画面でEnterを入力して検証実施
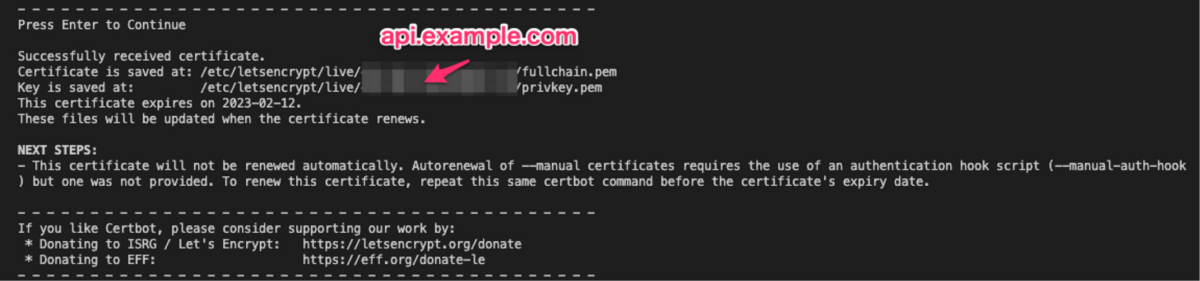
以上の手順で得られたfullchain.pemとprivkey.pemを、GCPのセルフマネージド証明書の要素としてコンソールなりAPIなりからアップロードし、しばし待てば準備完了です。
トラフィック移行前の確認
証明書が有効かを確認するためには最終的にはAレコードを変更することになりますが、ローカルで /etc/hosts を編集してドメインとCLBのIPを紐付ければローカル環境からは事前にHTTPSアクセスが有効か検証できます。
トラフィックを流す前にセルフマネージド証明書が有効化され浸透していることを確認することをおすすめします。
安全なトラフィック移行作業をどう行うか
さて、SSL証明書を事前に用意できたため、あとはドメインへのトラフィックをCloud Load Balancingに流してあげればOKです。
・・が、前述したようにドメインをそのままにすることと、段階的な移行や速やかな切り戻しを実現するため、このステップで必要となった工夫について記載していきます。
まずは、説明のため移行前のドメイン周りの状況を図示しておきます。
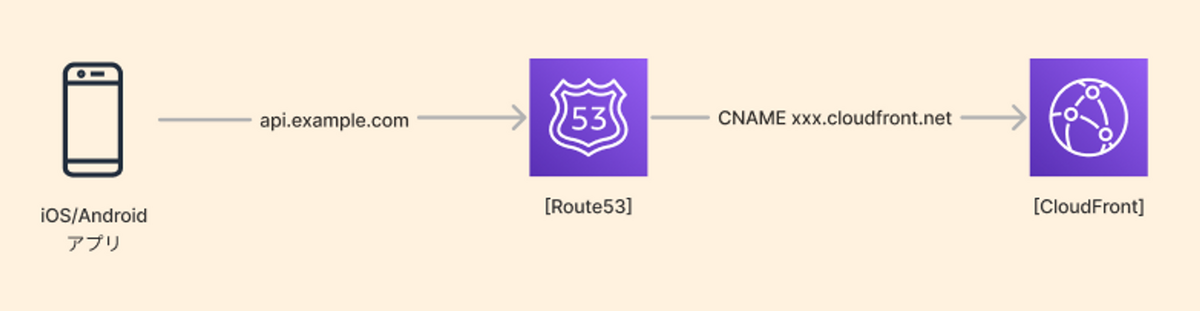
移行前は、Route53でホストしているドメインのCNAMEをCloudFrontに向け、そこからオリジンへ流すような構成を取っていました。
APIのドメインを変更しないことにしたため、上図で言うところのapi.example.comの向き先がGCP世界に向いている状態がゴールと言えます。
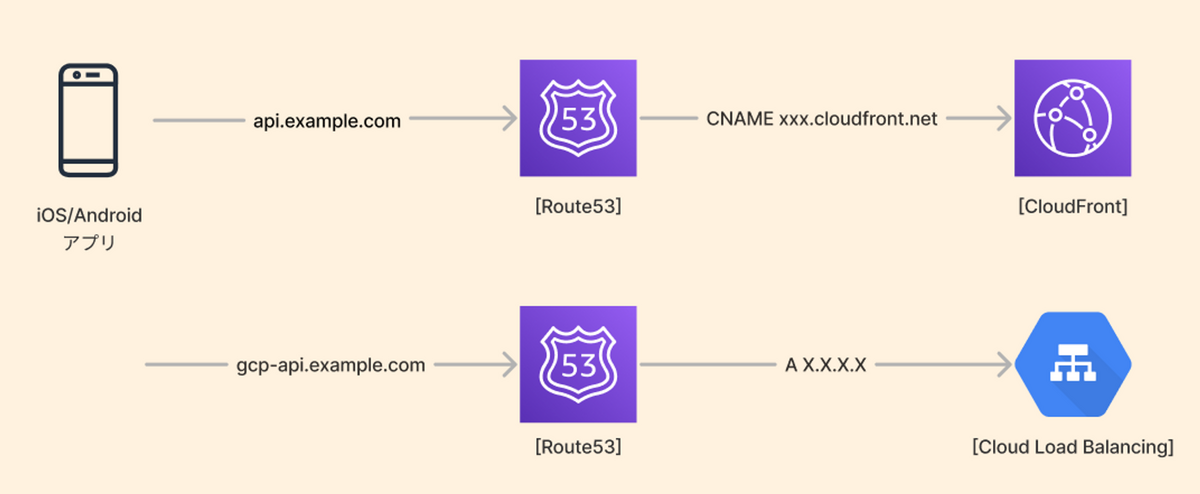
今回GCP上にデプロイしたAPIはCloud Load Balancingを最前段に置いています。CLBはAWSのALBやCloudFrontとは違ってドメインが振られず、ロードバランサーにIPを紐付けることで疎通させる仕組みとなっています。
そのため、CLBに紐付けたIPに向けたAレコードを作成することでドメインへのトラフィックをCLBに流すことになります。
ですが、利用中のドメインにはCNAMEがセットされているため追加でAレコードを設置できません。(ダウンタイムが許容できるなら、既存のCNAMEを外してバツっと差し替えても良いですが・・)
ではどうするのかというと、新ドメインでAレコードを作成して、そのドメインへのルーティングとして既存ドメインにCNAMEを作成します。
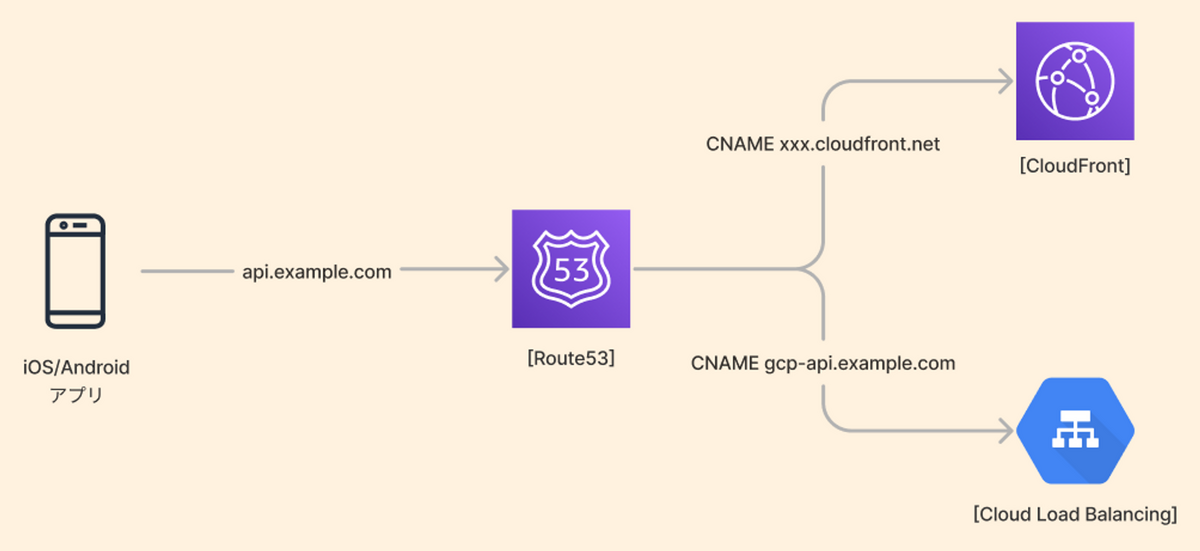
この構成を取ると、CNAMEでの加重ルーティングを用いることが出来るため、どのレコードに何%のトラフィックを流すか指定できます。
つまり、初期は10%程度GCPに流しておき、挙動に問題があればGCP側の加重を0にして戻す or 問題なければGCP側の加重を100にして全て流す、といったコントロールが可能です。
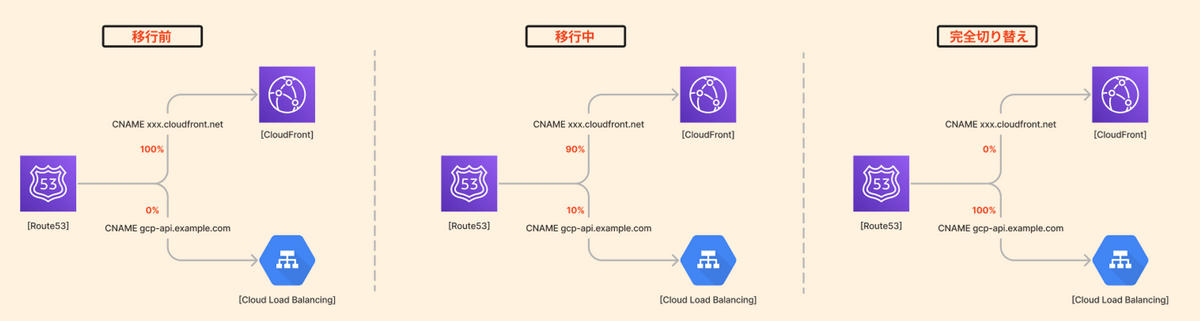
これで、課題としていた段階的な移行と速やかな切り戻しが実現できます。
まとめ
以上2パートの作業を組み合わせ、ダウンタイムなしで段階的にAPIのAWS->GCP切り替えを行うことができました。
実際の作業では、移行後のコストが嵩みすぎて一度AWSに戻したり、Cloud Load Balancingの後段のサービスを別のものに切り替えるイベントが発生したりと、何度か加重ルーティングに助けられたシーンがありました。
ワンチャンスで祈りながら移行・・ではなく、様子を見ながらゆっくり行える作戦で作業できたことが、精神的に本当に良かったですし運用工数も小さく絞れて大満足でした。
NewsDigestの根幹APIに関してはこれで移行完了となりましたが、JX通信社全体で見るとまだまだインフラでもアプリケーションでも大幅なリファクタリング・リアーキテクチャが望ましい箇所が残っています。
制約は諸々ありますが、その中で理想を追求し、プロダクトを自分の手で育てていきたい!といった志を持った仲間を募集していますので、ぜひご連絡ください!