
背景
こんにちは!JX通信社シニアMLエンジニアのファンヨンテです。 JX通信社では 属人化しがちなR&Dをチーム開発するため社内共通のテンプレートコードを用いて機械学習が行われています。テンプレートコードにはハイパーパラメータ管理のパッケージとして、Hydraを用いています。
しかし、HydraとVertex AI (GCPのマネージドMLサービス)の相性が悪い部分があり、工夫なしではエラーになることがあります。 前回のブログでは、Hydraで書かれたコードでVertex AIのハイパーパラメータ調整を行うための工夫とサンプルコードを紹介しました。
本ブログでは、ML Pipelineの簡単な紹介の後に、Hydraで書かれたコードをVertex AI Pipelineで動作できるようにするための方法を記載しています。またサンプルコードも公開しているので、一人でも多くの人の参考になれば幸いです。
ML Pipelineについて
ML Pipelineとはなにか?
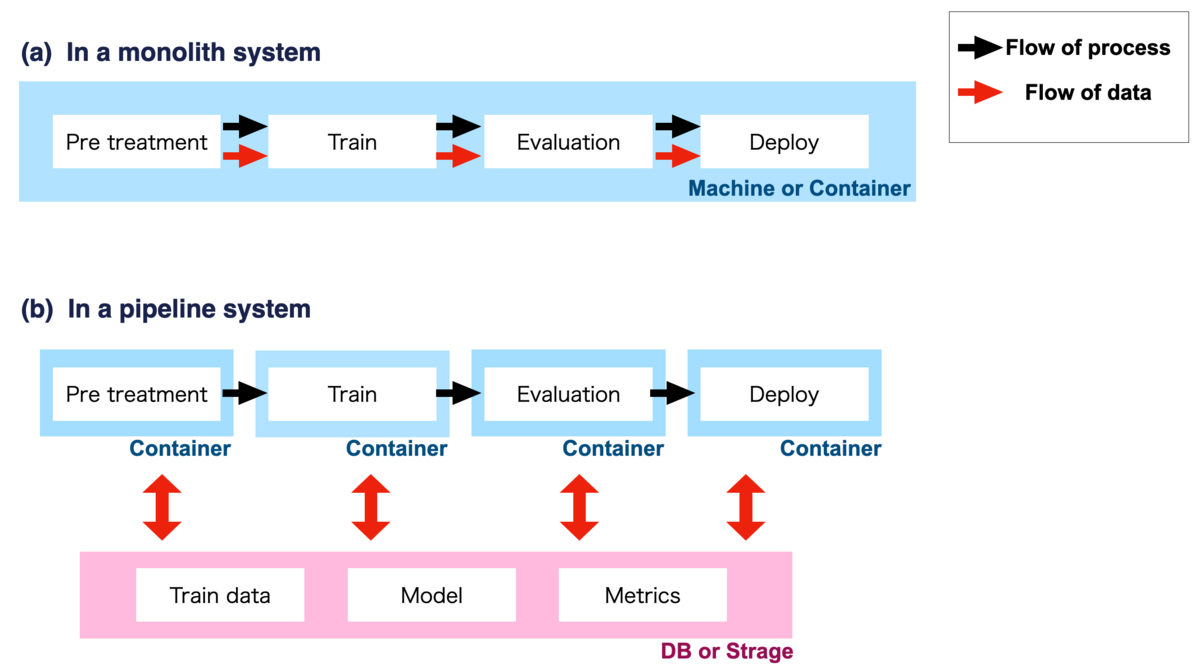
機械学習のトレーニングは、データの前処理、学習、評価等様々なプロセスによって構成されています。 これらのプロセスを、一つのマシーンまたはコンテナで行う学習システムはMonolith システムと一般的に言われます (図1 (a))。機械学習を初めて体験したときには、多くの方が Monolith なシステムで試したのではないかと思います。
一方、機械学習系のシステムの本番運用まで考慮したとき、
- データとモデルの再現性の担保
- 例 : それぞれのプロセスにランダム性が含まれると、すべてのプロセスを一貫して行うMonolith システムでは、結果が変化した要因がつかみにくい
- プロセスごとに求められるマシーンスペックが異なる
- 例 : ハイメモリが必要なプロセスもあれば、メモリではなくGPUが必要なプロセスもある
- プロセスが独立しているので、使い回しが容易
等の理由から、個々のプロセス (コンポーネントと一般的に呼ばれる)を独立させて処理を行う、Pipelineシステムによる学習が推奨されています (図1 (b))
ML Pipelineについてのより詳しい情報は what-a-machine-learning-pipeline-is-and-why-its-importantやFull Stack Deep Learningを御覧ください。 また、Googleのブログ (Rules of Machine Learning:Best Practices for ML Engineering)では、MLの学習はPipelineの利用が前提に書かれています。
Vertex AI pipelineとは?
学習の Pipeline をコンポーネントに分け、それぞれを異なるマシーンで実行するようなシステムをゼロから構築することは、非常に複雑で困難であることが想像できると思います。 一方、Vertex AI Pipelineを利用することで、図2に示すような GCP の他のサービスと連携しながら、ML Pipelineを容易に構築することができます。
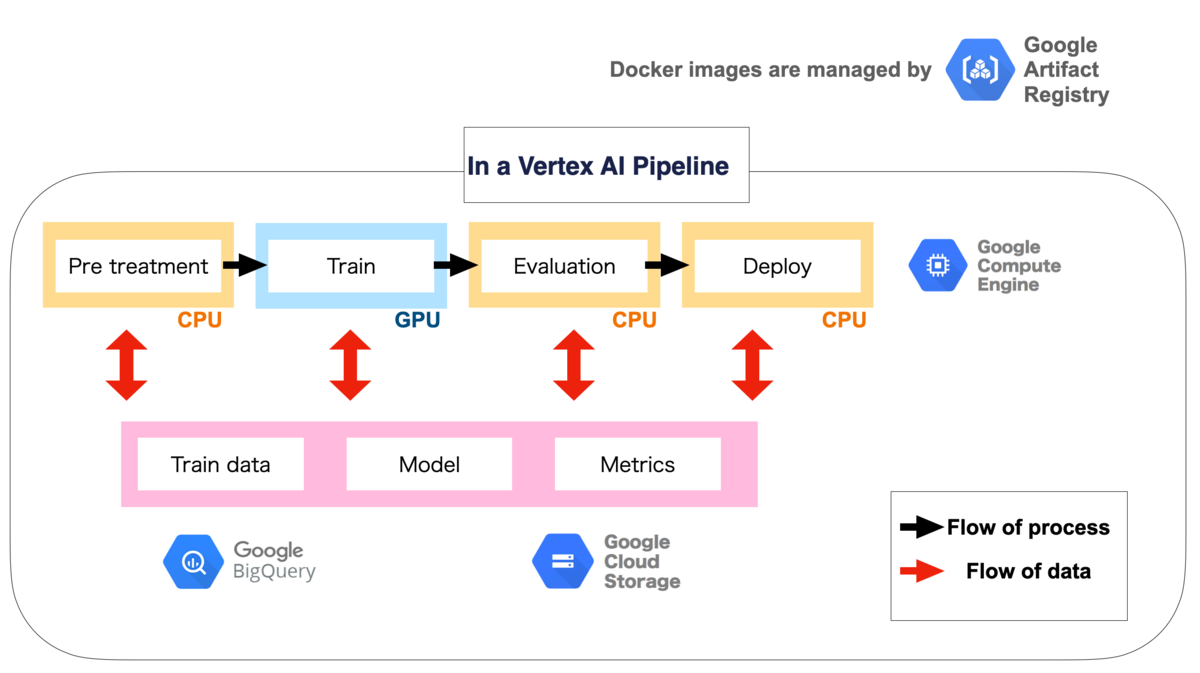
Vertex AI Pipeline のその他メリットや、より詳細な部分については、以下のような素晴らしいブログやsample codeが公開されているので、是非ご覧になってください。特に著者がML Pipelineに入門する際、杉山様のブログを理解し、サンプルコードを手元で動かすことは、たいへん大きな成長につながったので、ぜひ皆様も一度サンプルコードを手元で動かしてみてください!Vertex AIを用いることで、ML Pipelineの構築を楽に行えることが体験できると思います。
HydraとVertex AI Pipeline
Hydraはハイパーパラメーター管理のライブラリとして、非常に素晴らしく、この例のように様々な学習用のコードが取り組まれています。 一方、Hydraで記載されたコンテナを、Vertex AI Pipelineのコンポーネントとして利用しようとした場合、問題が発生します。
問題点
Vertex AIでは、各コンポーネントにわたす引数を、yamlファイルのargsで定義します。 この際、Vertex AIの公式の書き方では
command: [python3, main.py] args: [ --project, {inputValue: project}, ]
のように記述する必要があります。
このように argsを記述した場合、コンテナには以下のような argparse形式のコマンドが渡されます。
python3 main.py --project <value of project>
一方、Hydraを用いたコンテナには
python3 main.py project=<value of project>
の形式でコマンドを引き渡す必要があり、工夫なしで実行するとエラーになります。
解決法
yamlファイルの書き方を
command: [python3, main.py] args: [ 'project={{$.inputs.parameters["project"]}}', ]
に変更する必要があります (図3)。

Vertex AIの一般的に利用される引数と、それに対応する変換方法は表1に掲載しています。
表1 : Vertex AIで推奨されている引数の渡し方をHydra用変換する対応表
| 公式の書き方 | Hydra形式に変換する方法 |
|---|---|
| --input-val, {inputValue: Input_name} | input-val={{$.inputs.parameters['Input_name']}} |
| --input-path, {inputPath: Input_path_name} | input-path={{$.inputs.artifacts['Input_path_name'].path}} |
| --output-path, {outputPath: Output_path_name} | output-path={{$.inputs.artifacts['Output_path_name'].path}} |
実際に動かしてみた
シンプルな例として、MNIST分類のAI PIpelineの構築を紹介します。sample codeはこちらで公開しております。READMEにコードをベースとした具体的な動作方法を記載したので、ぜひ皆様体験してみてください。
Pipelineは、
data prepare : MNISTのデータをダウンロードする
train : 学習を行う
の2つのコンポーネントから構成されます。 どちらのコンポーネントもHydraで書かれています。
各コンポーネントのコンテナイメージを作成
data prepare
data prepareのコンポーネントはこちらで記載されています。このコンポーネントも管理を容易になるようHydraで記載しています。
具体的には、必要な関数を functions フォルダに書き込みます。その後、config.yamlで処理したい関数とその引数を記述することで、処理する関数をパラメーターとして決定することができます。
train
学習コンポーネントは前回ご紹介したHydraとPyTorch Lightningを用いたコードを用いて行いました。
各コンポーネントの設定を行う
コンポーネントの設定はconfig フォルダで行われています。configの書き方は公式のドキュメント、または、Kubeflowのサイト参照ください。
ここの注意点として、argsは公式の書き方をしてしまうと、エラーになるので、表1のように書き直しが必要です。
各コンポーネントの接続
定義したコンポーネントの接続はpipeline.pyで定義され、コンパイルが行われます。 コンパイルで作成されたjsonをVertex AI Pipelineに提出すると、Pipelineが実行されます。
まとめ
今回はHydraで書かれたコードをVertex AI Pipelineで動作できるようにするときの問題点と工夫について記載させていただきました。 このブログが皆様にとって参考になれば幸いです。