こんにちは!JX通信社シニアMLエンジニアのファンヨンテです。私は普段から、顧客にとって価値の高い(言い変えれば、顧客を幸せにできる)AIを開発することをモットーに仕事に励んでます。そのためには、AI開発の速度を高め、様々なAIやその見せ方を顧客に試していただくことで、顧客の幸福度を上げる方向性を見出していく必要があります。
効率性を高め、AIの開発速度を上げるために、JX通信社では様々な工夫を行っており、これまでもブログで紹介してきました。
今回はその取り組みの中でも、あるClassのデータを集中的に追加する時の背景やTipsと注意点についてまとめます
目次
背景
分類をおこなうAIの開発において、とあるClassだけ学習データの数が少なかったり、新たに分類しなければならないClassが追加されることはよくあります。このような場合の対策として、「とあるClassの学習用データだけを追加で作成し、AIの精度を上げたい」と考えることがあると思います。
例として、スイーツに関するアンケートの回答文を、
- Class 1 : 『甘さに関する言及をしている』
- Class 2 : 『しょっぱさに関する言及をしている』
- Class 3 : 『味に関する言及なし』
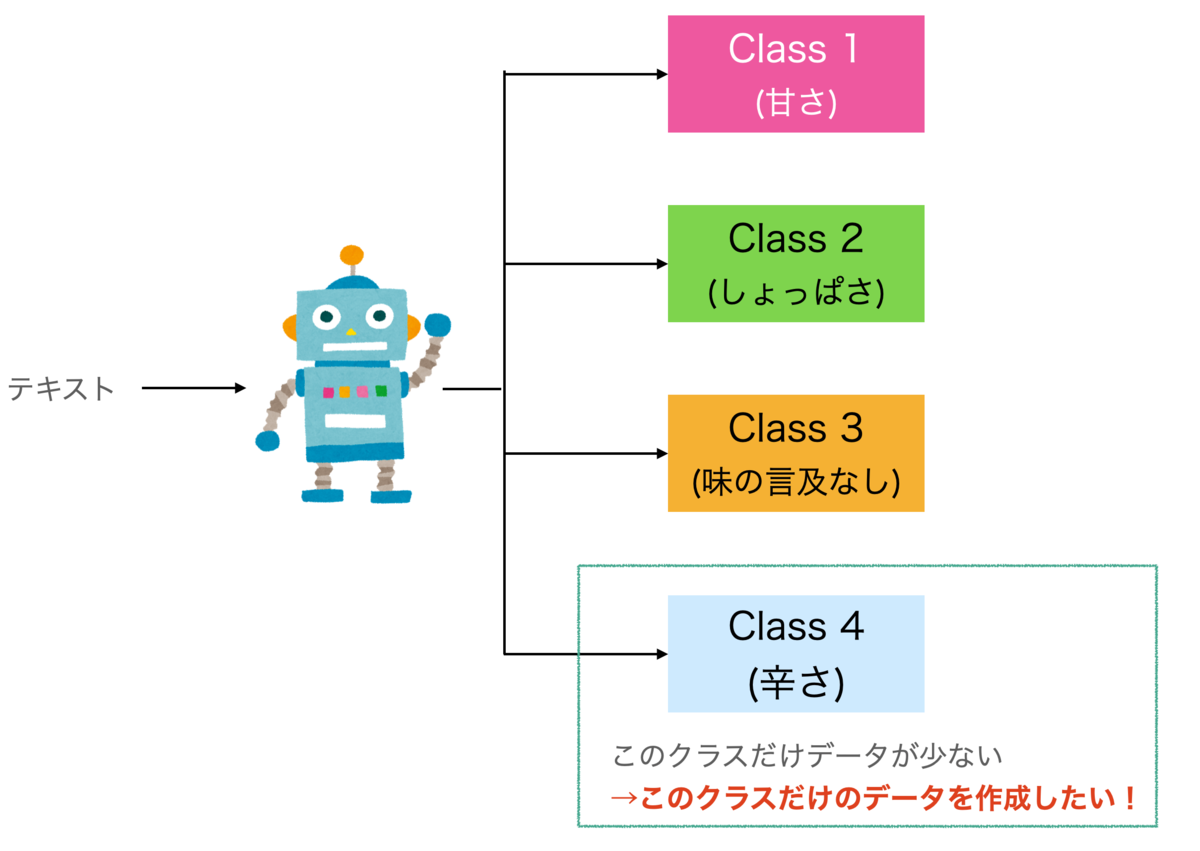
の3つのClassに分類するAIがありました。ビジネス的な要望で、新たに
- Class 4 : 『辛さに言及している』
のClassを追加する事になりました (図1)。しかし、これまで辛さに言及しているテキストにラベルを付けてなかったので、辛さのデータが少ないです。そこで、新たに辛さに言及しているテキストを収集し、Class 4の学習用データに追加していく状況を考えます(図1)。
データ作成の手順
簡単なフィルター
アンケートデータの中から、『辛い』という意図が含まれるテキストを取得するために
(からい OR 辛い OR からっ) が含まれる
という条件でフィルターして集めるとします。しかし、このような条件で集めたデータには
ここ最近、本当に辛いから運動して気分転換しよ
のように「味」としての意味ではなく、「つらさ」を意図したものが含まれてしまう可能性があります。これらは本来 味の言及なしのラベルに該当し、辛さに言及している 学習データとして追加するにはふさわしくありません。
このようにキーワードマッチング程度のフィルターでは誤ったラベルが混入する可能性が高いため、そのまま学習データに加えるのはリスクがあります。 *1
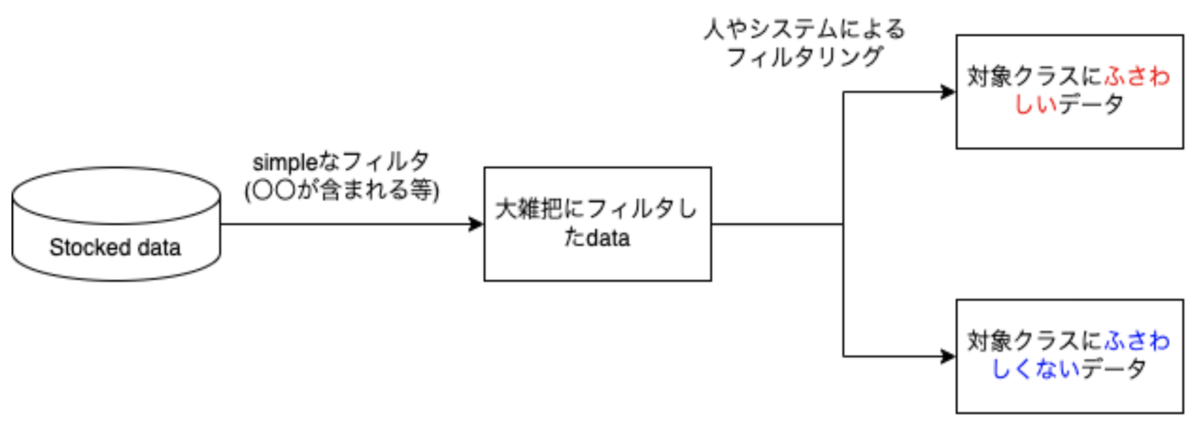
Classにふさわしいデータを判別するシステムを作成する
簡単なフィルタリングだけでは学習データに適さず、その中からClassにふさわしい学習データ( 味としての辛い のデータ)を選び出す必要があります (図2)。その際、人間の力に頼らざるを得ないですが、自動翻訳機やAIを利用することで自動化出来る部分もあります。(本ブログの最後に補足として後述しています。)
対象Classにふさわしいデータも、ふさわしくないデータも、共に大事
Classにふさわしいデータの選別が終了後、本来の目的通り 味としての辛い と言及しているデータだけを対象Classに追加し、対象Classにふさわしくないデータは廃棄して学習に進んでしまいがちです。しかし、この手法をとってしまうと、AIは 味としての辛いと言及していないデータも 味としての辛いと言及したと間違った予想をしてしまいます(図3)。
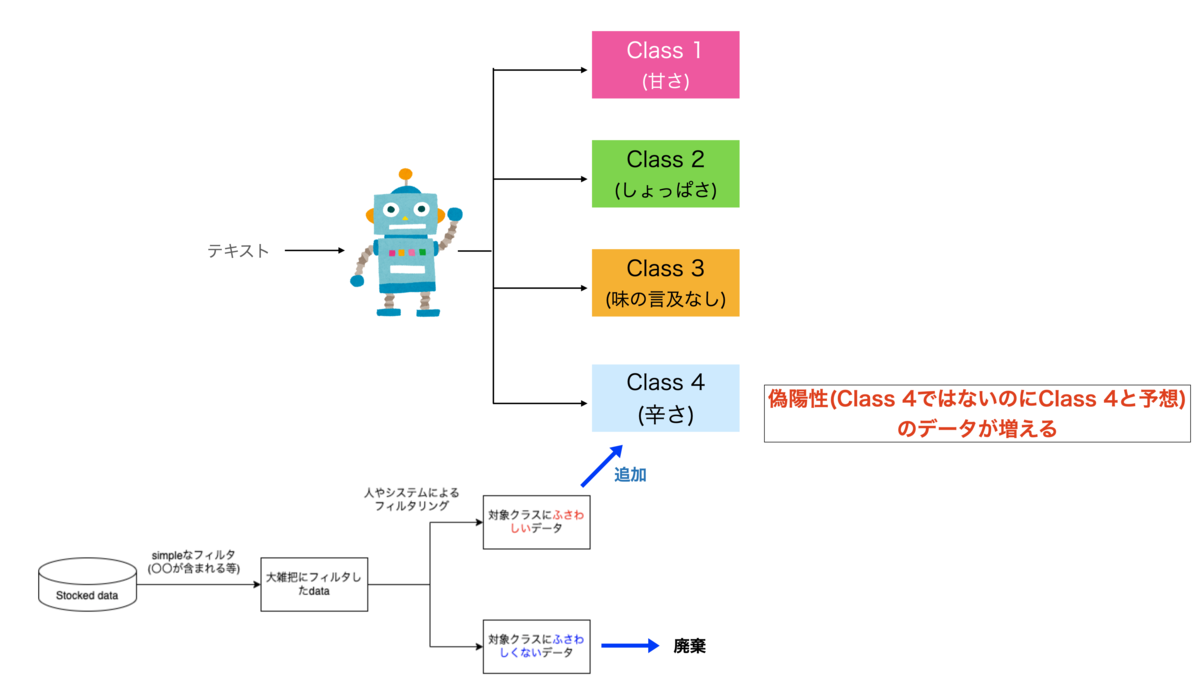
この問題はAIに対象Classに入るべきデータだけを教えて、入るべきではないデータを教えなかったことが原因です。したがって、この問題を解決するためには、対象にふさわしいデータだけではなく、ふさわしくないと選別されたデータの両方を学習データに加える必要があります (図4)。
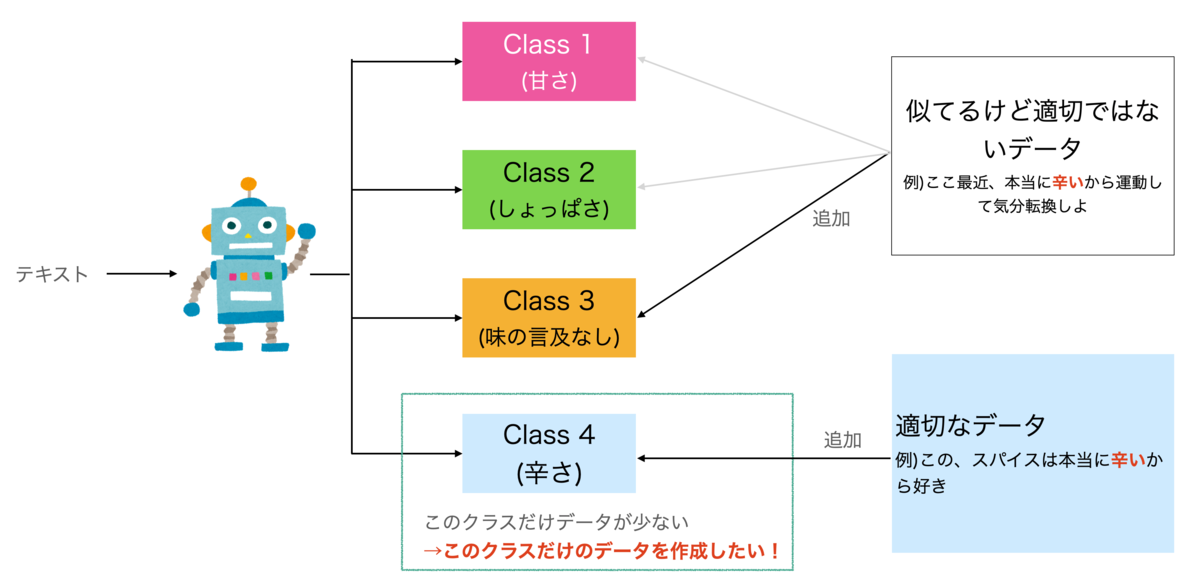
そのためには、対象Classにふさわしくないデータ全てに他のラベルを付与し、学習データに追加する必要があります。 しかし、このラベル付けの作業には多くの時間的、金銭的コストが掛かかるため、できれば避けたいです。そこで本ブログでは自動的にラベル付けをする方法を最後に紹介します。
対象Classにふさわしくないデータに再度ラベルを付ける
対象Classにふさわしくないデータ全てに、手動でラベルを付与することは非常に労力がかかります。そこで、対象Classを除いたデータで学習させたAI (図5 上)を用いて、対象Classに属さなかったデータを予想させ、それをラベルにすることで、大量のデータであってもラベルをつけることが出来ます (図5 下)。*2
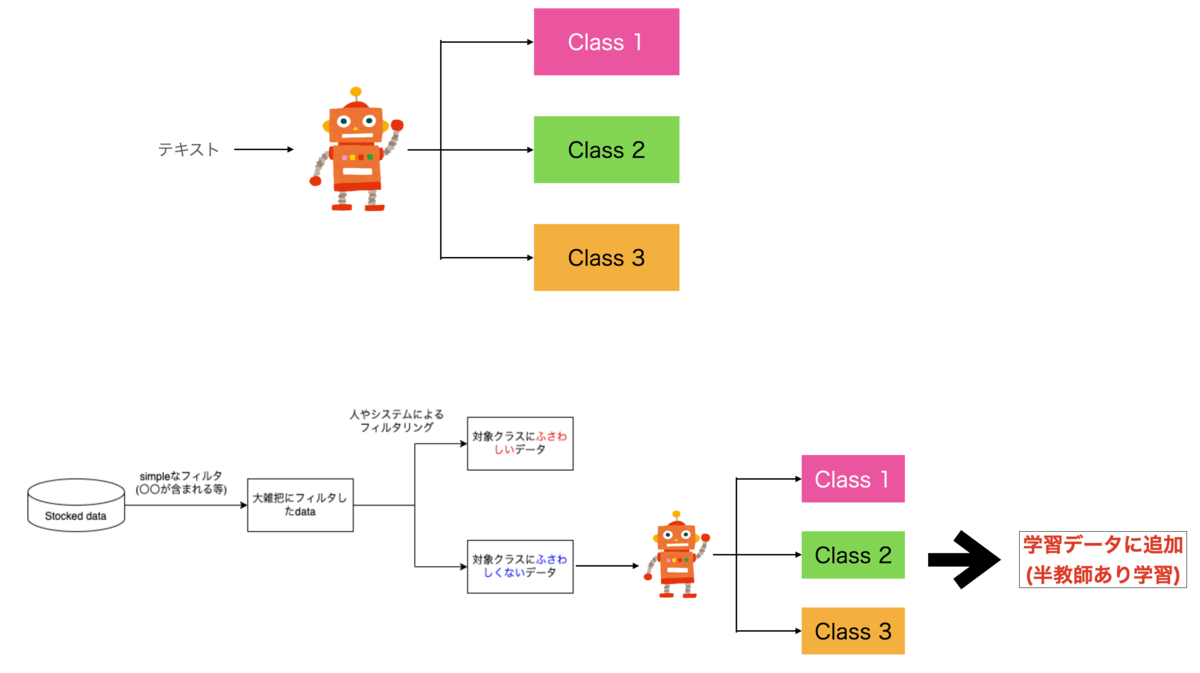
このように、対象Classにふさわしいデータだけではなく、ふさわしくないデータの両方をうまく利用することでAIの精度向上を達成することができます
まとめ
AIをビジネス運用していると、とあるClassの分類精度が他のClassより大事な状況や、環境の変化でAIに求められる性能が変化することは多々あります。その要求にAIがうまく対応するために、とあるClassだけ特別にデータを作成したいと思うことはAIエンジニアにとって比較的あるあるなのではないでしょうか?
この時、対象ClassにふさわしいデータだけをそのClass に追加する方法を思いつきがちですが、この方法では精度が上昇しないどころか、下がる場合もあります。実際、筆者も色んな人の協力や、システムを利用して作成したデータを追加したのに、AIの精度が上昇しなくて苦労した経験があります。その大きな原因は、対象Classにふさわしくないとされたデータを破棄したことにありました。したがって、AIの精度向上のためには、本ブログで紹介したように、対象Classにふさわしくないが対象クラスに近いデータを他のClassに追加して、そのクラスに入るべきではないデータも同時に教える必要があります。
また、筆者がこのブログでもう一つ伝えたかったこととして、アノテーションを手動ですべて行うことは無理があるため、なるべく簡素化するための方法を考える必要があるということです。
本ブログでは、筆者が行った工夫の例として、
- 自動翻訳機を用いた同音異義語の分類
- AIによる仮ラベル (本ブログでは以下の2つ)
を紹介しました。その他にも、MLM (Masked Langage Model)を用いた同音異義語の分類等、様々な工夫も考えられます。
読者の皆さまが同様な状況になった時、この情報が役立つことを願っています。また、本ブログで紹介したもの以外の原因や工夫も考えられますので、なにか思いつくことがあれば私のtwitterにお知らせください。
※ このドキュメントは文書分類の話ですが、画像分類を含めたその他の種類についての同様に適応できる考えです。
補足
本ブログの補足として、データのラベル付けをある程度自動化するためのテクニックを紹介します。
補足① : 翻訳機を利用して、同音異義語を区別する
機械翻訳では文脈まで考慮されるので、日本語の同音異義語も翻訳すると、他の単語に変換されることを利用出来ることもあります。
例として、味として適切なデータである
このスパイス辛いからホント好き
を英訳すると (DeepLを使用)
I really like this spice because it's hot.
のように辛い(からい)は hot や spicy に変換されます
一方、味として適切でない
ここ最近、本当に辛いから運動して気分転換しよ
を英訳すると (DeepLを使用)
It's been really hard here lately, so I need to get some exercise and change things up.
となり、 辛い(つらい)は hard に変換されます
このように、機械翻訳をし、日本語の同音異義語を別の単語にすることで意味によるフィルタリングができることがあります。
一方で、この手法では一定確率でノイズ(ラベルの誤り)が発生してしまうリスクもあります。ここで発生するノイズの割合が低ければ、AIを用いたデータのクレンジングの利用も筋が良いと思います。
補足② : 学習データを作成するためだけのAIを構築する
人や翻訳機で全てのデータをアノテーションするのは、時間やお金のコストがかかってしまいますが、ある程度のデータだけは人力で溜めて、 味としての辛いデータ or not を診断するだけのAIを新たに開発することも考えられます。
このAIが一定水準以上の精度を得られることが担保できれば、学習データのアノテーションを半自動 & 高速に作成することも出来ます。
※注意 : ここで、ふさわしいデータ or not を診断できるAIを作成できるなら、これをサービスで利用すればいいのでは?と思うかもですが、このAIは簡単なフィルタリングを通した後のデータに対しての分類AIなので、汎化性能は少なくフリーテキストのデータの推論には向いていません。