JX通信社シニア・エンジニアで, プロダクトチームのデータ活用とデータサイエンスのあれこれ頑張ってるマン, @shinyorke(しんよーく)です.
最近ハマってるかつ毎朝の日課は「リングフィットアドベンチャー*1で汗を流してからの朝食」です. 35日連続続いています.
話は遡ること今年の7月末になりますが, JX通信社のデータ基盤の紹介&「ETLとかバッチってどのFW/ライブラリ使えばいいのさ🤔」というクエスチョンに応えるため, このようなエントリーを公開しました.
このエントリー, 多くの方から反響をいただき執筆してよかったです, 読んでくださった方ありがとうございます!
まだお読みでない方はこのエントリーを読み進める前に流して読んでもらえると良いかも知れません.
上記のエントリーの最後で,
次はprefect編で会いましょう.
という挨拶で締めさせてもらったのですが, このエントリーはまさにprefect編ということでお送りしたいと思います.
今回はprefectで簡単なバッチシステムを作って動かす, というテーマで実装や勘所を中心に紹介します.
prefectをはじめよう
prefect #とは

簡単に言っちゃうと, Pythonで開発されたバッチアプリのFrameworkで,
The easiest way to automate your data.
(意訳:あなたのデータを自動化していい感じにするのに最も簡単な方法やで)
がウリとなっている模様です.
公式リポジトリのREADME.mdの解説によると,
Prefect is a new workflow management system, designed for modern infrastructure and powered by the open-source Prefect Core workflow engine. Users organize Tasks into Flows, and Prefect takes care of the rest.
(意訳:prefectは今風のインフラストラクチャーに合わせて設計されたFrameworkで, 開発者はTaskとFlowを書いてくれたらあとはPrefect Coreがいい感じにワークフローとして処理するやで)
というモノになります.
ちなみにHello worldはこんな感じです.
from prefect import task, Flow, Parameter @task(log_stdout=True) def say_hello(name): print("Hello, {}!".format(name)) with Flow("My First Flow") as flow: name = Parameter('name') say_hello(name) flow.run(name='world') # "Hello, world!" flow.run(name='Marvin') # "Hello, Marvin!"
@taskデコレーターがついた関数(上記の場合say_helloがそう)が実際に処理を行う関数.
処理に必要な引数を取ったり関数を呼んだりするwith Flow("My First Flow") as flowの部分を開発者が実装, あとはよしなにやってくれます.
こんにちはprefect
という訳で早速prefectをはじめてみましょう.
一番ラクな覚え方・始め方は公式のリポジトリをcloneしてチュートリアルを手元で動かすことかなと思っています.
※私はそんなノリでやりました.
$ git@github.com:PrefectHQ/prefect.git $ cd prefect $ pip install prefect SQLAlchemy
SQLAlchemyが入っているのはひっそりとチュートリアルで依存しているからです(小声)*2.
ちなみにPython3.9でも動きました👍
ここまで行けば後はチュートリアルのコードを動かしてみましょう.
$ cd examples/tutorial $ python 01_etl.py
このブログを執筆した2020/12/18現在では, 06_parallel_execution.py以外, 滞りなく動きました.
ひとまずこんな感じで動かしながら, 適当に書き換えながら動かしてやるといい感じになると思います.
軽めのバッチ処理を作ってみる
exampleをやりきった時点で小さめのアプリは作れるんじゃないかなと思います.
...と言っても, 何にもサンプルが無いのもアレと思い用意しました.
baseballdatabankというメジャーリーグ⚾️のオープンデータセットを使って超簡単なETLバッチのサンプルです.*3
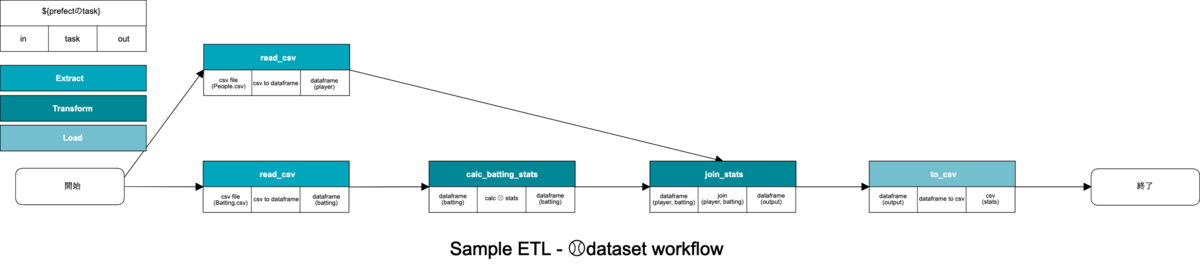
- 選手のプロフィール(People.csv)を読み込み
- 打撃成績(Batting.csv)を読み込み&打率等足りない指標を計算
- 選手プロフィールと打撃成績をJOINしてのちcsvと出力
というETL Workflowなのですが, こちらの処理はたったこれだけのコードでいい感じにできます.
import logging from datetime import datetime import pandas as pd import click from pythonjsonlogger import jsonlogger from prefect import task, Flow, Parameter logger = logging.getLogger() handler = logging.StreamHandler() formatter = jsonlogger.JsonFormatter() handler.setFormatter(formatter) logger.addHandler(handler) logger.setLevel(logging.DEBUG) @task def read_csv(path: str, filename: str) -> pd.DataFrame: """ Read CSV file :param path: dir path :param filename: csv filename :return: dataset :rtype: pd.DataFrame """ # ETLで言うとExtractです logger.debug(f'read_csv: {path}/{filename}') df = pd.read_csv(f"{path}/{filename}") return df @task def calc_batting_stats(df: pd.DataFrame) -> pd.DataFrame: """ 打率・出塁率・長打率を計算して追加 :param df: Batting Stats :return: dataset :rtype: pd.DataFrame """ # ETLで言うとTransformです logger.debug('calc_batting_stats') _df = df _df['BA'] = round(df['H'] / df['AB'], 3) _df['OBP'] = round((df['H'] + df['BB'] + df['HBP']) / (df['AB'] + df['BB'] + df['HBP'] + df['SF']), 3) _df['TB'] = (df['H'] - df['2B'] - df['3B'] - df['HR']) + (df['2B'] * 2) + (df['3B'] * 3) + (df['HR'] * 4) _df['SLG'] = round(_df['TB'] / _df['AB'], 3) _df['OPS'] = round(_df['OBP'] + _df['SLG'], 3) return df @task def join_stats(df_player: pd.DataFrame, df_bats: pd.DataFrame) -> pd.DataFrame: """ join dataframe :param df_player: player datea :param df_bats: batting stats :return: merged data :rtype: pd.DataFrame """ # ETLで言うとTransformです logger.debug('join_stats') _df = pd.merge(df_bats, df_player, on='playerID') return _df @task def to_csv(df: pd.DataFrame, run_datetime: datetime, index=False): """ export csv :param df: dataframe :param run_datetime: datetime :param index: include dataframe index(default: False) """ # ETLで言うとLoadです logger.debug('to_csv') df.to_csv(f"{run_datetime.strftime('%Y%m%d')}_stats.csv", index=index) @click.command() @click.option("--directory", type=str, required=True, help="Baseball Dataset Path") @click.option("--run-date", type=click.DateTime(), required=True, help="run datetime(iso format)") def etl(directory, run_date): with Flow("etl") as flow: run_datetime = Parameter('run_datetime') path = Parameter('path') # Extract Player Data df_player = read_csv(path=path, filename='People.csv') # Extract Batting Stats df_batting = read_csv(path=path, filename='Batting.csv') # Transform Calc Batting Stats df_batting = calc_batting_stats(df=df_batting) # Transform JOIN df = join_stats(df_player=df_player, df_bats=df_batting) # Load to Data to_csv(df=df, run_datetime=run_datetime) flow.run(run_datetime=run_date, path=directory) if __name__ == "__main__": etl()
pandasの恩恵に授かって*4prefectのお作法に従うと比較的見通しの良いworkflowが書けますね, というのがわかります.
今回はcsvファイルを最終的なinput/outputにしていますが,
- ストレージにあるjsonをいい感じに処理してBigQueryにimport
- AthenaとBigQueryのデータをそれぞれ読み込んで変換してサービスのRDBMSに保存
みたいな事ももちろんできます(taskに当たる部分でいい感じにやれば).
この辺はデータ基盤やETL作りに慣れていない人でもPythonの読み書きができれば直感的に組めるのでかなりいいんじゃないかと思っています.
その他にできること&欠点とか
今回は「ひとまずprefectでETLっぽいバッチを作って動かす」という初歩にフォーカスしていますが, 実はこのprefect高機能でして,
- タスクの進行状況をGUIで表示可能(AirflowとかLuigiっぽい画面)
- 標準でDocker, k8sの他GCP, AWS, Azure等のメジャーなクラウドサービスでいい感じに動かせる
など, かなりリッチな事ができます.
一方, 使ったときのネガティブな感想としては,
- 色々できるんだけど, 色々やるために覚えることはまあまあたくさんある.
- 色々できるんだけど, それが故に依存しているライブラリとかが多く, 自前でホスティングするときのメンテ効率とかはちょっと考えてしまう.
- ちゃんとデバッグしてないのでアレですが, 並列処理の機構がホントに並列で動いてるか自信がないときがある🤔
と, 心配なポイントもいくつかありました.
前のエントリーにも記載しましたが,
ETLフレームワーク, 結局どれも癖がありますので長いおつきあいを前提にやってこうぜ!
結局のところこれに尽きるかなあと思います*5.
結び - 今後のこの界隈って🤔
というわけでprefectを使ったいい感じなバッチ開発の話でした.
データ基盤や機械学習のWorkflowで使うバッチのFWやライブラリはホント群雄割拠だなあと思っていまして,
AirflowのDAGがシンプルに書けるようになったり(ほぼprefectと同じ書き方ですよね*6), BigQueryのデータをいい感じにする程度のETLならほぼSQLで終わる未来がくる(かも)だったりと, この界隈ホント動きが活発です.
このエントリーの内容もきっと半年後には古いものになってるかもですが, トレンドに乗り遅れないように今後もチャレンジと自学自習を続けたいと思います!
なおJX通信社ではそんなノリで共に自学自習しながらサーバーサイドのPythonやGoでいい感じにやっていく学生さんのインターンを募集しています.
おそらく私が年内テックブログを書くのは最後かな...
皆様良いお年を&来年また新たなネタでお会いしましょう!
*1:執筆時点のLVは58, 運動負荷はMAXの30です. 筋肉が喜んでます💪
*2:このエントリーのため久々に試していましたがあっ(察し)となります.
*3:なぜ⚾のオープンデータ化というと, 私の趣味かつ手に入りやすい使いやすいオープンデータだったからです.
*4:この程度の処理だとprefectよりpandasの優秀さが目立つ気はしますが, デコレーターでいい感じにflowとtaskに分けられているあたりprefectの設計思想は中々筋が良いと言えそうです.
*5:ETLに限った話ではないのですが, 選んだ以上メンテをちゃんとやる, 使い切る覚悟でやるってことかなあと思っています.
*6:余談ですがprefectの作者はAirflowのコントリビューター?作者??らしいです.