こんにちは、サーバーサイドエンジニアの @kimihiro_n です。 今回はSentryというエラー集約管理システムをGo言語で扱う場合の知見を共有したいと思います。
Sentry とは
Sentryはエラーの集約管理を行うためのシステムで、作成したアプリケーション内で発生したエラーを一括で収集して見やすく管理することができます。
類似のエラーをグルーピングして発生頻度を確認したり、エラーの発生状況をSlackのようなチャットツールに通知してくれたりします。 予期しないエラーが発生したとき、生のログを見なくてもSlackやWebのUIで確認出来るのはとても便利です。 バックエンドからフロントエンドまで幅広い言語に対応しているためシステムのエラーを一括で集約が可能です。

JX通信社ではエラー管理ツールとしてSentryを広く利用しており100を超えるシステムが登録されています。 Sentryはセルフホスト版のSentryも存在していて、当初はサーバーを構築して利用していたのですが運用の煩雑さからマネージドなサービス版を利用するようになりました。
sentry-goを使ってみる
SentryのGo言語向けSDKの sentry-go、触ったことない方もいると思いますので、まずは使い方を軽く紹介します。
package main import ( "log" "time" "github.com/getsentry/sentry-go" ) func main() { // SDK初期化 // Options については後述 err := sentry.Init(sentry.ClientOptions{}) if err != nil { log.Fatalf("fail to init sentry: %s", err) } defer func() { // panic の場合も Sentry に通知する場合は Recover() を呼ぶ sentry.Recover() // サーバーへは非同期でバッファしつつ送信するため、未送信のものを忘れずに送る(引数はタイムアウト時間) sentry.Flush(2 * time.Second) }() // なにかのプログラム err = hoge.Exec() if err != nil { // err を sentry へ送信する sentry.CaptureException(err) } }
このような形でSDKをセットアップすると、エラーやPanicが発生した場合にSentryへとデータが送られます。
Recover() は内部でGo言語の recover() を呼んでpanicから脱しSentryへの送信を行います。
なのでゴルーチンとかで処理が分岐している場合はゴルーチン側でも sentry.Recover() を呼ばないと捕捉できないケースがあります。
APIサーバーの場合はSentry側でWebFrameworkのインテグレーションを用意してくれています。 ユーザーのリクエスト情報(パスやメソッド、リモートアドレスなど)をエラーと合わせて記録してくれるので原因の調査がしやすくなるので利用可能であれば使ってみましょう。
おすすめのClientOptions
Sentryの初期化時に渡せるClientOptionsについて参考程度におすすめの設定を紹介します。 詳細については公式ドキュメントを参照してください。
DSN:- Sentry のDSNを入れるオプションです。
- プロジェクトごとに専用のDSNが発行されるので、これをソースコードにセットすることで正しくセットアップができます。
- が、ソースコードから設定しなくても
SENTRY_DSNという環境変数をSDKが参照してくれるのでセットせず利用することが多いです。 - DSNが未設定の場合でもエラーにはなりません。
- 未設定時の場合、sentry.CaptureException()などを呼んでも何も起こりません。
Debugを有効にするとEventを破棄したログが出ます。
- ローカルの開発環境ではSentryを使わず開発し、検証用のサーバーにあげるときにSentryのログを有効にする使い方が簡単にできます。
Environment:- 環境を入れるオプションです。
stagingproductionなどを入れておくと本番で起きたエラーなのかがすぐ分かります。- この Env を元に通知する Slack のチャンネルを変えるといった使い方も可能です。
AttachStacktrace:- CaptureMessageを呼んだ時にスタックトレースを付与するかのオプションです
- ソースコードの位置がわかるので基本付けておいて損はないかと。
IgnoreErrors:- 文字列がマッチするエラーを無視することが出来ます
- Sentry はサーバーにエラーを飛ばした数で料金プランが変化するので、対処する必要は特にないけれど大量に出てしまうエラーなどはここでセットしておくと安心です。
他にもパフォーマンス計測用のオプションなどがありますが今回は割愛します。
Goでの困りごと
エラーの収集は上記で出来るのですが、Go言語の場合すこし困ったことが起こります。
Go 1.13からエラーの Wrap 機能が提供されるようになり、捕捉したエラーをfmt.Errorfでラップして上位に返すパターンをよく書くようになりました。
... err := json.Unmarshal([]byte(`{"wrong json"}`), &result) if err != nil { return fmt.Errorf("fail to parse result: %w", err) } ...
ラップをすることでエラーの抽象度があがり、呼び出す側が意図を把握しやすくなります。
ところがこうしてラップされたエラーをSentryに渡すと

このような形で処理されてしまいます。
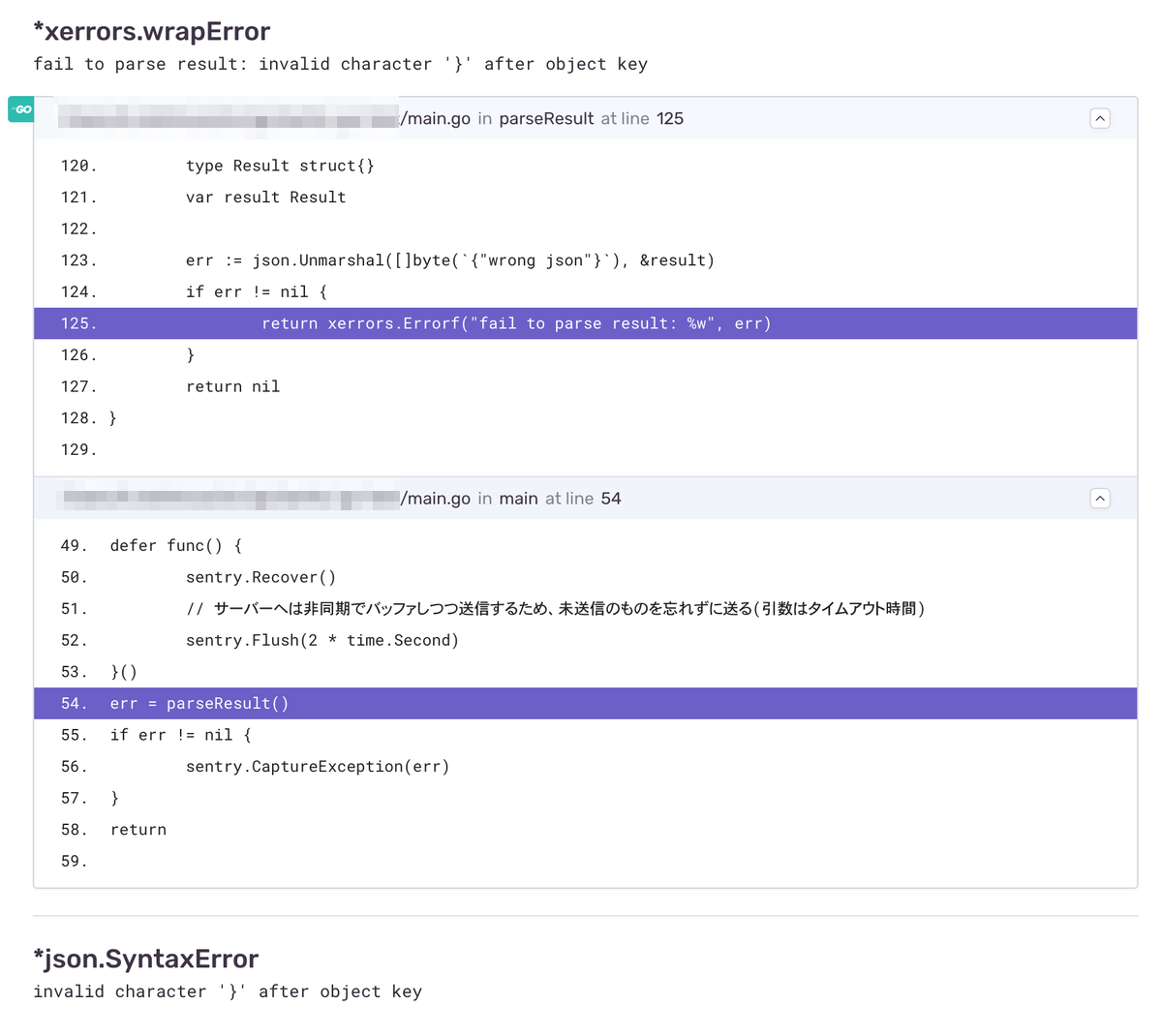
実際に発生しているエラーは json の Unmarshal のエラーのはずですが、画面の方では *fmt.wrapError のエラーとして扱われ、ソースの情報もエラー発生箇所ではなく sentry.CaptureException(err) を呼び出した箇所になってしまっています。
エラーの原因を調査をするとき、CaptureExceptionを呼び出した箇所というのはあまり重要ではなく、実際にWrap前のエラーが発生した箇所や、fmt.Errorfでラップを行った箇所を知らせてくれるほうが有用です。
Python版のSentryの場合、SDKをセットアップすればよしなにスタックトレースを出してくれたのですが、Goの場合、言語の標準エラーにスタックトレースの機能が存在しないため、少し不便な出力になります。
またエラーが「*fmt.WrapError」として扱われてしまうと、fmt.Errorf でラップしたエラーがすべて同列のエラーとして集約されてしまう問題もあります。Sentryの場合、エラーのグループごとに通知を設定することが多いので、異なるエラーが同一にまとめられてしまうと重要なエラーを見逃してしまうリスクがあります。
このあたりもPython版だとSDK入れるだけだったのですが静的言語なのでいろいろ制約がありそうです。
- エラーが発生した箇所のソースコードがSentryで見られる
- fmt.Errorf でラップした異なるエラーは異なるエラーとして扱われる の2つが実現できればSentryでの取り扱いがよくなりそうです。
Go でも Sentryを見やすくする
スタックトレースについては pkg/errors など外部エラーパッケージを利用すると、Sentryがそこからスタックトレースを取り出して表示してくれることが分かりました。
- pkg/errors
- xerrors
- go-errors/errors
- pingcap/errors
ドキュメントとして明文化されていないものの、現在この4つのパッケージに対応してそうです。
https://github.com/getsentry/sentry-go/blob/master/stacktrace.go#L75
pkg/errors は有名なエラーパッケージでしたが、現在レポジトリがArchiveされてしまっているため新規では利用しづらいです。
xerrors はGo公式がメンテナンスしているエラーパッケージです。 Wrap などの機能が Go 1.13 で本体に取り込まれたものの、スタックトレースの機能については取り込まれなかったためパッケージが残っています。スタックトレースのみを表示する用途であればこのパッケージで十分そうです。
xerrors でスタックトレース
... err := json.Unmarshal([]byte(`{"wrong json"}`), &result) if err != nil { return xerrors.Errorf("fail to parse result: %w", err) } ...
fmt.Errorf の部分を xerrors.Errorf に変えてみました。
今度は sentryでエラーを投げるところだけではなくてちゃんとエラーが発生したところをトレースできてますね。
じゃあソース内の fmt.Errorf を一括で変換してしまえばいいかというとそうでもなくて、今度は過剰にスタックトレースが付与されてしまいます。
xerror でラップしたものを更に xerror でラップすると、それぞれに対して別々のスタックトレースが付与されてしまい、Sentry ではそれらを全部列挙しようとします。本当に見たい部分以外のスタックトレースが入ってしまうので調査のための情報が逆にノイズになってしまいます。
なので、以下の方針でラップすると無駄のないエラーハンドリングが出来るかと思います。
- Goのパッケージやライブラリが吐くエラーは xerror.Errorf でラップする
- 自分で書いた関数のエラーをラップするときは fmt.Errorf を使う
xerror のスタックトレース付きエラーを fmt.Errorf でラップしてもちゃんとスタックトレースを展開してくれ、fmt.Errorf した部分もトレースが残っていくので上記の方針で進めると無駄なくエラーにスタックトレースを付与できると思います。
wrap したものを適切にグルーピングする
fmt.Errorf でラップしたものがSentry上でまとめられてしまう問題についても見ていきます。
https://github.com/getsentry/sentry/issues/17837
GitHubのIssueにヒントがないかみてみたのですが明確な解決法が見当たらず、SDKでタイトルを上書きするのがいいのではないかというコメントで終わっています。
GoのSentrySDKにはBeforeSend というフックが用意されており、こちらを利用することでタイトルの書き換えが可能になるみたいです。
![]()
- グループ名(上段太字): *xerrors.wrapError
- サマリ(下段): fail to parse result: invalid character '}' after object key
となっているところを
- グループ名: fail to parse result
- サマリ: invalid character '}' after object key
のように書き換えてあげれば、最後にWrapしたメッセージがグループ名として利用できそうです。
BeforeSend のシグネチャは
BeforeSend: func(event *sentry.Event, hint *sentry.EventHint) *sentry.Event
のようになっており、渡されたeventを書き換えてreturnしてあげれば上書きが可能です。
Sentryの captureException を利用した場合、Sentry側でエラーのグルーピングのキーになるのは event.Exception 配列の最後の Type が利用されるみたいたいです。
なので wrapError の場合だけ上書きしてみることにします。
err := sentry.Init(sentry.ClientOptions{
Debug: true,
AttachStacktrace: true,
// BeforeSend のフックで Event を書き換え
BeforeSend: func(event *sentry.Event, hint *sentry.EventHint) *sentry.Event {
for i, _ := range event.Exception {
exception := &event.Exception[i]
// fmt.wrapError, xerrors.wrapError 以外は何もしない
if !strings.Contains(exception.Type, "wrapError") {
continue
}
// 最初の : で分割(正しく Wrapされていないものは無視)
sp := strings.SplitN(exception.Value, ":", 2)
if len(sp) != 2 {
continue
}
// : の前を Typeに、 : より後ろを Value に
eexception.Type, exception.Value = sp[0], sp[1]
}
return event
},
})
先ほどのエラーを再度送信してみると、

無事エラーを書き換えることが出来ました。
今回のケースでは一律で一番外側の Wrap を剥がしていますが、処理を変えればより柔軟にカスタマイズできそうです。
まとめ
- Sentry は便利
- エラーを文字列でラップして使うときは以下のルールにするとスタックトレースが扱いやすい
- Goのパッケージやライブラリが吐くエラーは xerror.Errorf でラップする
- 自分で書いた関数のエラーをラップするときは fmt.Errorf を使う
- BeforeSend のフックでイベントを加工することで有意なエラーグルーピングを実現できる
参考
- https://incident.io/blog/golang-errors
- https://tech.buysell-technologies.com/entry/adventcalendar2021-12-21
*1:The Gopher character is based on the Go mascot designed by Renee French. The design is licensed under the Creative Commons 3.0 Attributions license.