JX通信社の CTO の小笠原(@yamitzky)です。本日は、最近社内で検証している API クライアントの「Insomnia」や、Insomnia を活用したチームでの API 開発の効率化についてご紹介します。
Insomnia とは
Insomnia は、オープンソースの API クライアントです。API 通信を GUI で直感的に検証・保存できる、というのが最も基本的な機能です。似たようなツールだと Postman などが有名だと思います。
Insomnia は一般的な REST API だけでなく、GraphQL や gRPC の API にも対応したツールです。JX通信社では、NewsDigest や FASTALERT などのサービスで GraphQL を活用しているため、GraphQL にネイティブ対応しているのは非常に便利です。
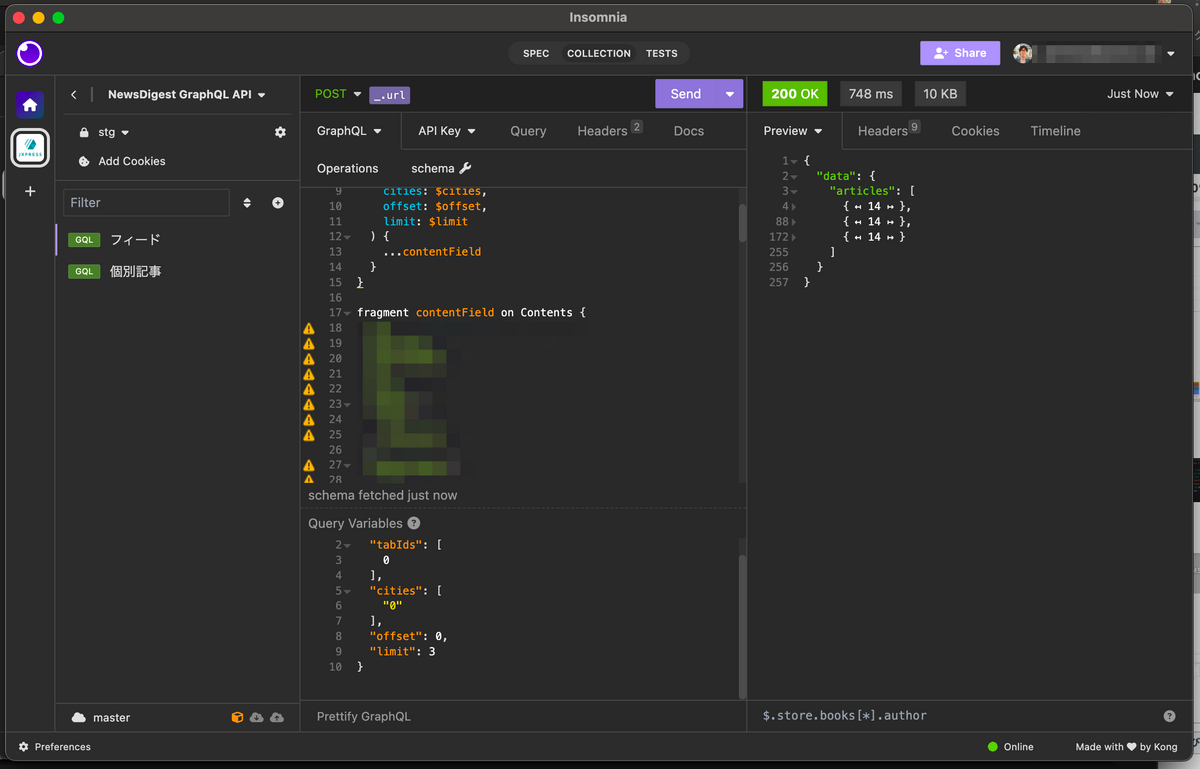
また、後述のように Insomnia にはチーム開発のための機能(コラボレーション機能)が備わっており、保存したリクエストのリストを他の人と共有することもできます。
Insomnia を導入するモチベーション
Insomnia の最も基本的な使い方は API クライアントとしての使い方です。これだけであれば、GraphQL Playground や、Swagger UI などでも事足りるかと思います。
今回、Insomnia を導入することで、次のような課題を解決できないかと考えました。
1. API 通信の様々なユースケースの記録
同じ通信エンドポイント(URL)に対して「◯◯でフィルターする場合」「◯◯でソートする場合」「不正なデータを入れた場合」といった複数のユースケース(利用想定)が紐づくことがありますが、これらを網羅的に保存できるようにしたいです。
2. スキーマ定義がされていない社内 API のドキュメント
一部、昔開発した API サーバーなどでは、GraphQL や OpenAPI でのスキーマ定義がされていないものが残ってます。これらの API の使い方のドキュメントについても、統一した場所に保存しておきたいです。
3. 成果物の共有
スプリントレビューのような成果報告会で営業側のメンバーに GUI で API を叩いてもらう場合や、普段 API の開発に入っていないエンジニアメンバーにさっと共有したい場合があります。
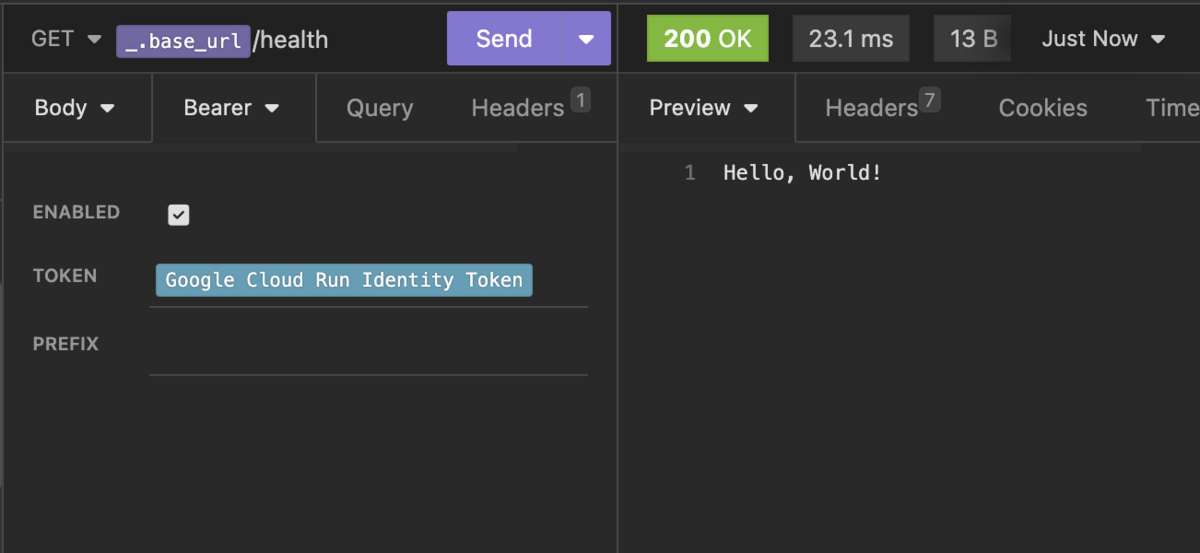
4. 認証方法が複雑なプロジェクトのデバッグ
Google Cloud の Cloud Run で開発した認証付き API だと、Bearer Token を都度 CLI で生成して設定する必要があります。このような認証が設定されていても、容易にデバッグできることが望ましいです。
これらの「保存」と「共有」の課題を解決するために、今回 Insomnia の導入を検討しました。特に、本稿で紹介するような基本機能だけであれば、Insomnia の共有機能は無料で使えるのが嬉しいポイントです(料金プラン)。
Insomnia の共有機能
Insomnia では、右上の「+Share」ボタンを押すことで、他のメンバーに共有することができます。
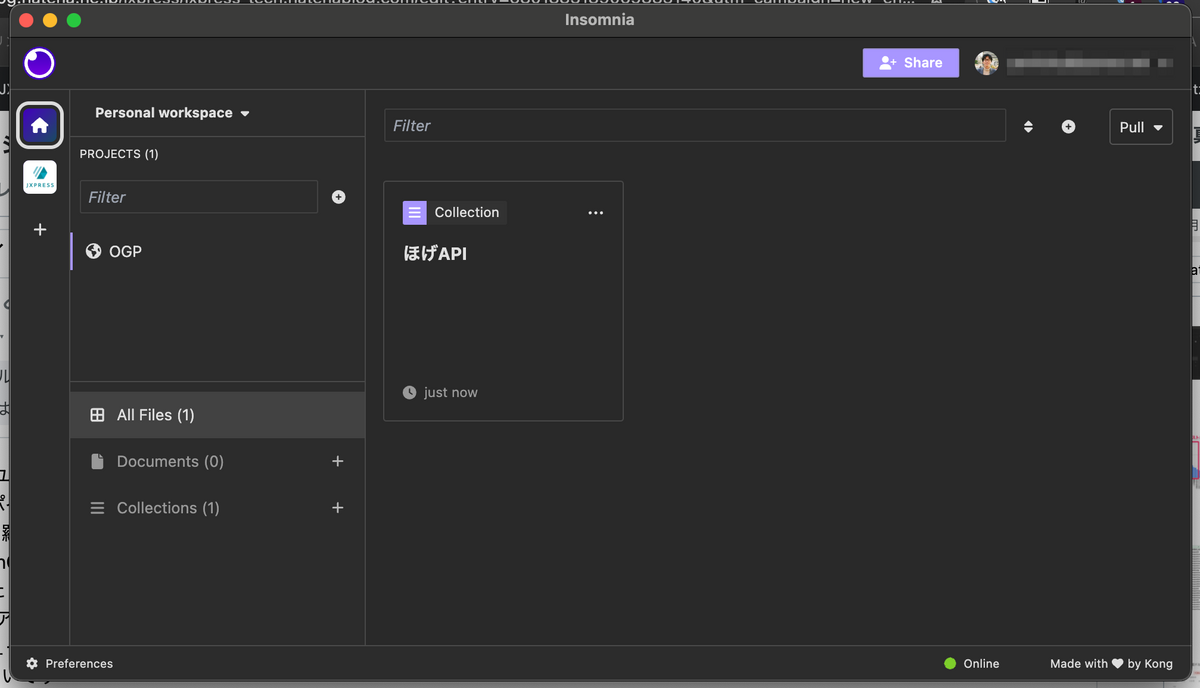
その際にデフォルトで設定されているのが E2EE(エンドツーエンド暗号化) です。利用者が管理する鍵を元に、保存したリクエスト内容は暗号化されます。逆に、パスワードを忘れるとアクセスできなくなってしまうため気をつけてください*1。
共有されたプロジェクトは、 他のユーザーと共同編集ができます。好みが分かれるところですが、Notion や Google Docs のような同期的な共同編集ではなく、Git のような概念 (commit / push / pull) による共同編集がベースとなっています。プロジェクトの環境変数(例:API の URL) を共有することもできます。
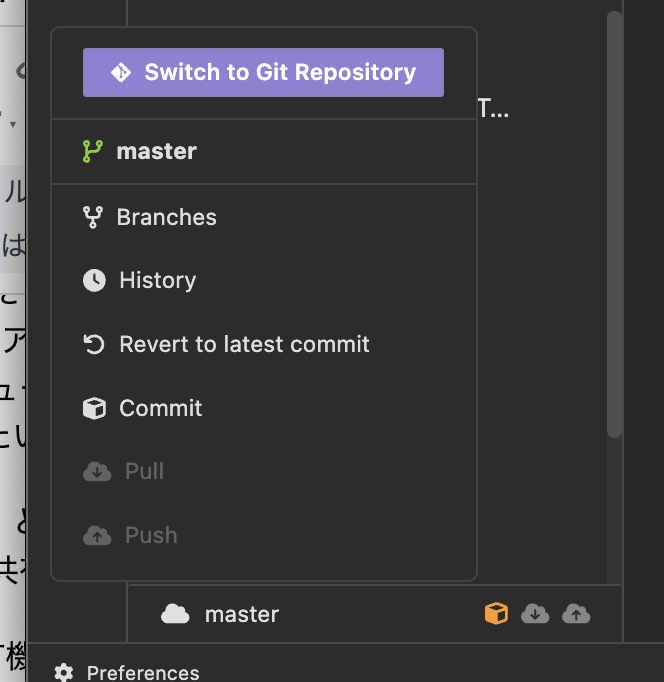
有償プランでは、実際に Git のリポジトリと紐づけたりもできるようです。
その他の便利機能
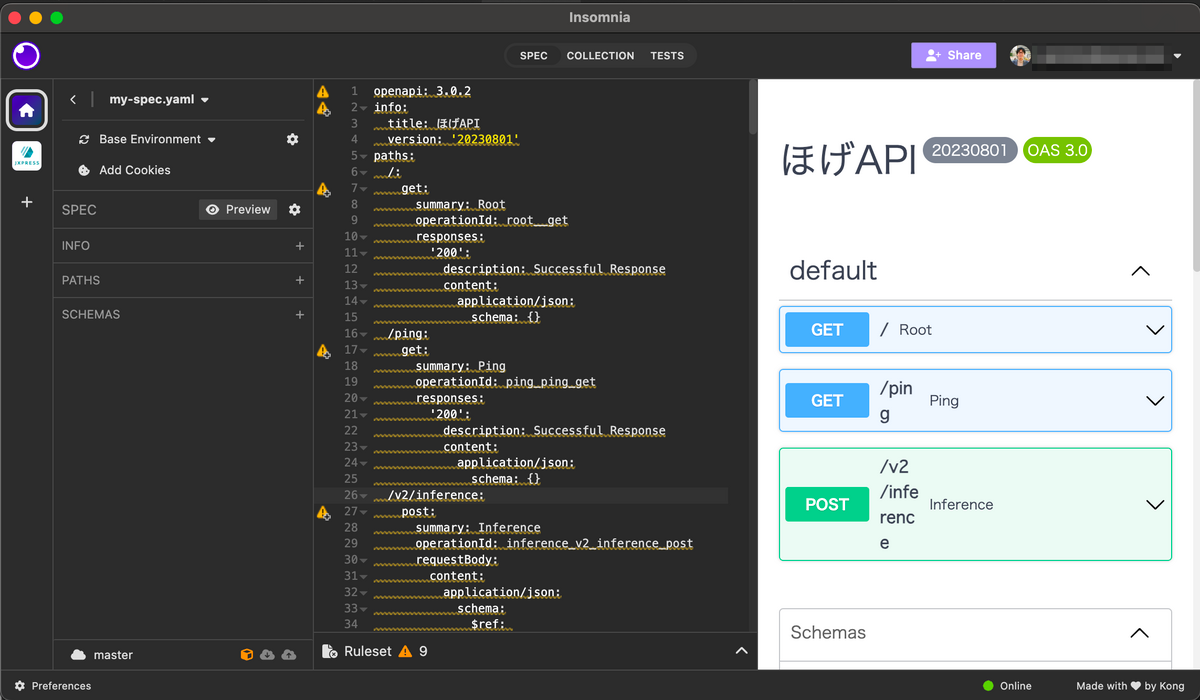
OpenAPI
Insomnia は、OpenAPI のエディターとしての機能も備わっています。バリデーションしてくれたり、定義を元に Insomnia のリクエストを一括生成→ curl や通信プログラムとしてコピーできるようにしたりもできるので非常に便利です。
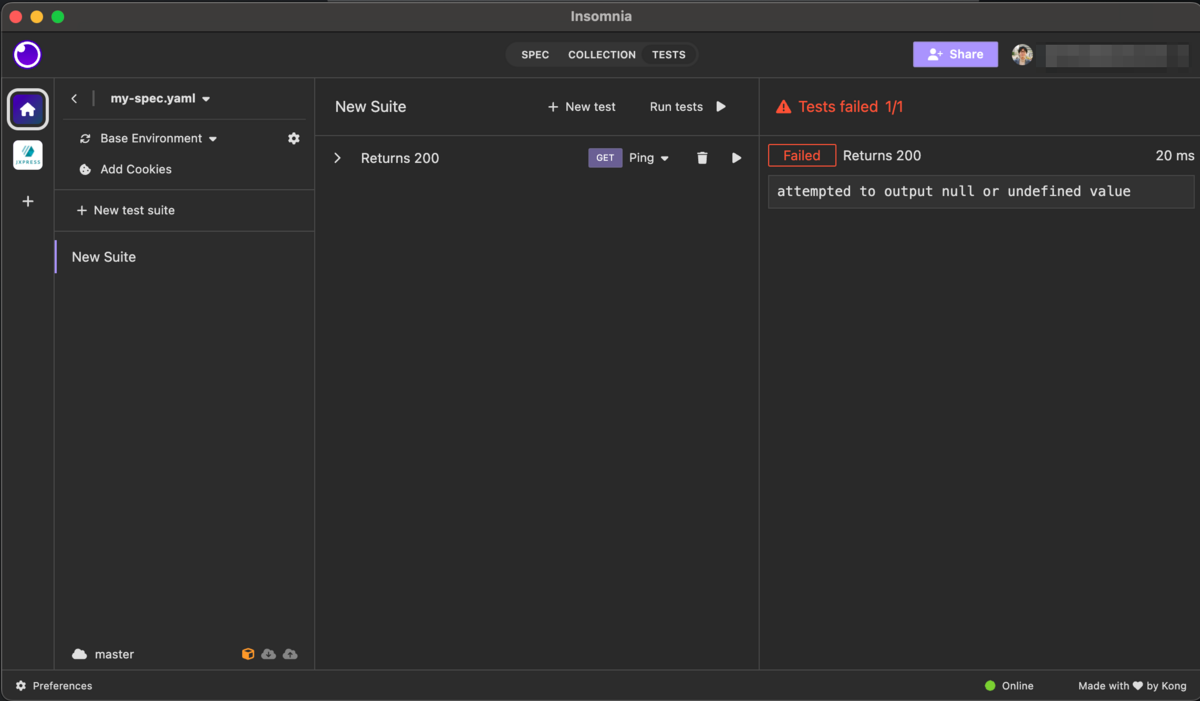
テスト
あまり検証していませんが、API 通信のテストケースも保存しておくことができます。システム障害発生時の初動調査やリリース前の一括動作チェックなどにも使えそうです。
変数埋め込み
Insomnia は環境変数の概念があり、これを DRY に埋め込むことができます。API のドメインや API キー等を設定し、本番/開発環境を切り替えるのにも便利です。環境変数の情報も他チームメンバーと共有することができます。また、逆に共有しない「Private enviromnent」を設定することもできます。
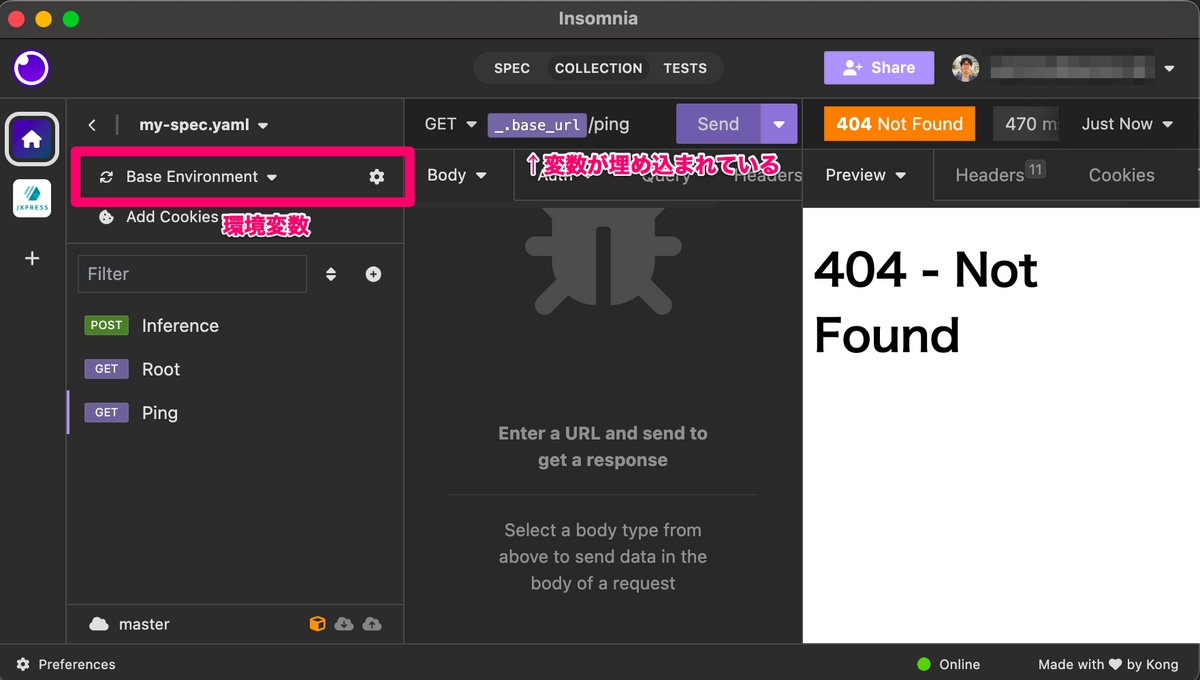
このような環境ごと設定値の埋め込みだけではなく、プロンプト(リクエスト実行時に発火するフォームダイアログ)の結果を埋め込む機能や、動的に生成した UUID やタイムスタンプ、OS 情報などを埋め込む「Template tag」という機能もあります。
外部プラグイン
実は、Template Tag の機能は、サードパーティーや独自に開発したプラグインによって、拡張することができます。これらのプラグインはPlugin Hubに公開されています。
例えば、Cloud Run の API の認証には cloud run auth を使えば自動的に認証情報を埋め込むことができます。プラグインのソースコードは公開されているので、参考にして自作もできますね。
まとめ
本稿では、Insomnia というツールと、検証している共有機能などの紹介をしました。無料で始めることができる、というのは、スタートアップ企業にとっては嬉しいのではないでしょうか?
他にみなさんが使っているツールあれば、ぜひコメントなどで教えていただけると嬉しいです。良いお年を!
*1:JX通信社ではパスワード管理ツールを使っています