こんにちは、データ基盤担当の @mapler です。今回は DataStream を活用して、Cloud SQL から BigQuery へのデータ同期についてお話しします。
Datastream の設定は基本的に Google Cloud のドキュメント従って行えますので、この記事では、実際の設定時に直面した課題や対策を中心に説明します。
背景:
データを BigQuery に同期することで得られるメリット
JX通信社の「FASTALERT」は、日本国内外の緊急情報をリアルタイムで配信するサービスです。災害情報や事故、事件、気象警報など、幅広い分野の緊急情報を網羅しており、長年にわたって膨大な災害データを蓄積しています。
社内や顧客から、蓄積したデータへのアクセス需要が高まってきました。
BigQuery からデータを利用できるようにすることで、次のような利点があります。
- 過去の特定の時期や地域で発生した事象を簡単に取得できるようになる
- BigQuery でデータの推移や統計情報を視覚的に分析しやすくなる
- 本番 DB にアクセスすることなく、負荷をかけずにデータを取得できる
課題:
これまで、社内のデータ基盤では CloudSQL から BigQuery への同期の仕組みを構築していましたが、リアルタイム同期ではなく、Cloud Composer (Airflow) を利用した Daily または Hourly のバッチタスクを使用していました。スケジュールタスクで Cloud SQL 連携クエリ によりデータを取得し、BigQuery に保存する方式です。しかし、この方法には以下の課題があります。
データの品質
バッチ処理の実行タイミングや取得範囲設定によって、BigQuery と CloudSQL のデータに差分が生じます。
- 過去の更新分が反映されない:たとえば取得範囲を「7日」と設定した場合、7日以上前のデータに更新があっても、それは BigQuery に反映されません。
- また、バッチの実行間隔を Daily に設定すると、データの反映に最大1日の遅延が生じる可能性があります。
実装コスト
テーブルごとに ETL(データの抽出・変換・ロード)と転送パイプライン設定(DAG)を実装する必要があり、設定コストがかさみます。
Datastream
Datastream は、サーバーレスで使いやすい変更データ キャプチャ(CDC)およびレプリケーション サービスです。このサービスを利用することで、データを最小限のレイテンシで確実に同期できます。
— 公式ドキュメントにより (https://cloud.google.com/datastream/docs/overview?hl=ja)
同期元(今回は Cloud SQL for MySQL)のバイナリログを利用してデータの変更履歴を読み取り、ストリーミングの形で BigQuery へ同期を行います。
Datastream の構築方法については、こちらの公式ドキュメントを参照することで簡単に設定できますが、実際設定してみたとき、ドキュメントが不十分でわかりにくかった部分や、環境に依存して発生した課題について紹介します。
課題1 ネットワーク構成
これは、Datastream を利用する際によく直面する問題の一つです。公式ドキュメントや他の多くのブログでも、この課題について議論されています。
Datastream では、同期元のデータベースがパブリック IP アドレスからの接続を受け入れるように構成されている必要があります。しかし、FASTALERT の DB(Cloud SQL)はプライベートネットワーク内にあり、Datastream から直接読み取ることができません。
そのため、プライベートネットワーク内でリバースプロキシサーバを構成する必要がありました。このリバースプロキシを利用することで、Datastream がプライベートネットワーク内の Cloud SQL にアクセスできるようにしました。
ネットワーク構成:
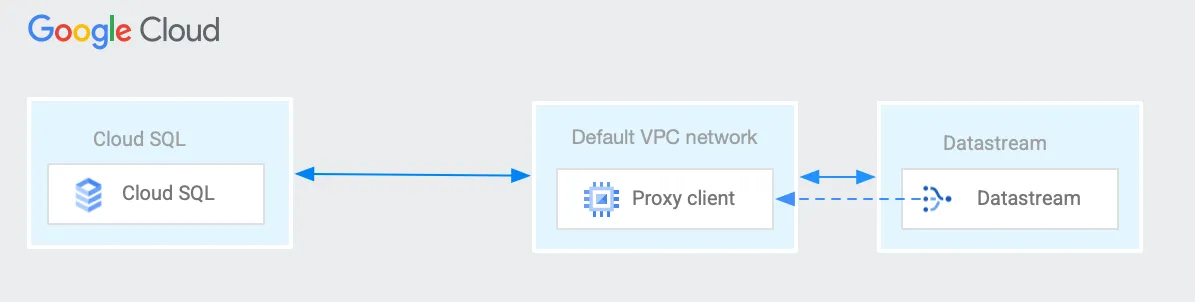
Compute Engine で n1-standard-1 の VM インスタンスを立ち上げ、Cloud SQL へのアクセスが可能になるように、ファイアウォールのネットワーク設定も行いました。
さらに、VM の起動スクリプトとして、以下のようにフォワード設定を行いました。
#! /bin/bash
export DB_ADDR=[IP]
export DB_PORT=[PORT]
export ETH_NAME=$(ip -o link show | awk -F': ' '{print $2}' | grep -v lo)
export LOCAL_IP_ADDR=$(ip -4 addr show $ETH_NAME | grep -Po 'inet \K[\d.]+')
echo 1 > /proc/sys/net/ipv4/ip_forward
iptables -t nat -A PREROUTING -p tcp -m tcp --dport $DB_PORT -j DNAT \
--to-destination $DB_ADDR:$DB_PORT
iptables -t nat -A POSTROUTING -j SNAT --to-source $LOCAL_IP_ADDR
これにより、Datastream のネットワークが正常に通信できることを確認でき、プライベートネットワーク内の Cloud SQL へのアクセスが確立されました。
課題2 転送費用の読みが甘かった
Datastream では、Cloud SQL のスキーマを読み取り、転送したいテーブルを選択することができます。
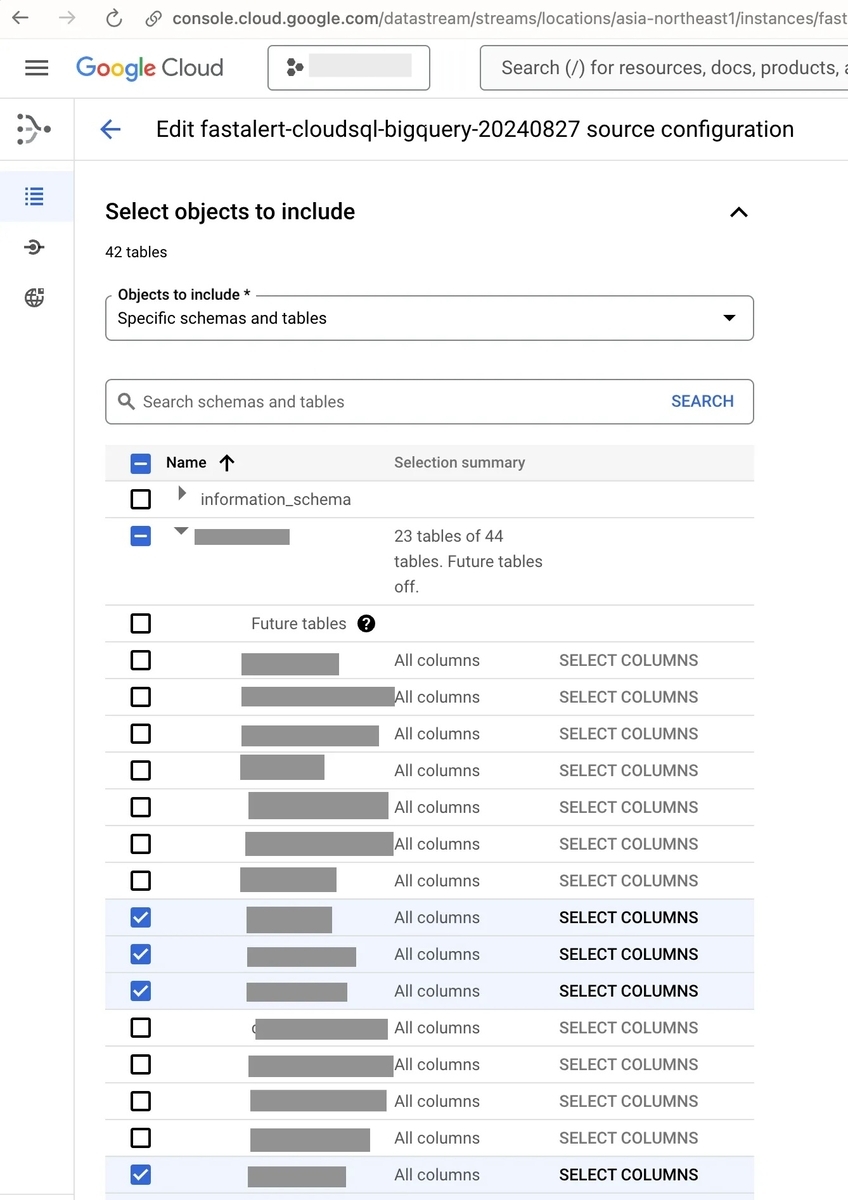
なるべく低コストで運用したいため、事前に行数が多いテーブルを転送対象から外しましたが、実際に運用してみると、想定よりも多い CDC(Change Data Capture)データの処理費用が発生していることがわかりました。
Datastream の OBJECTS 画面で転送実績を確認したところ、レコード数が少ないにも関わらず転送量が大きいテーブルがあることが判明しました。
このテーブルは変更が非常に頻繁で、大量の変更データが発生していたことが原因でした。
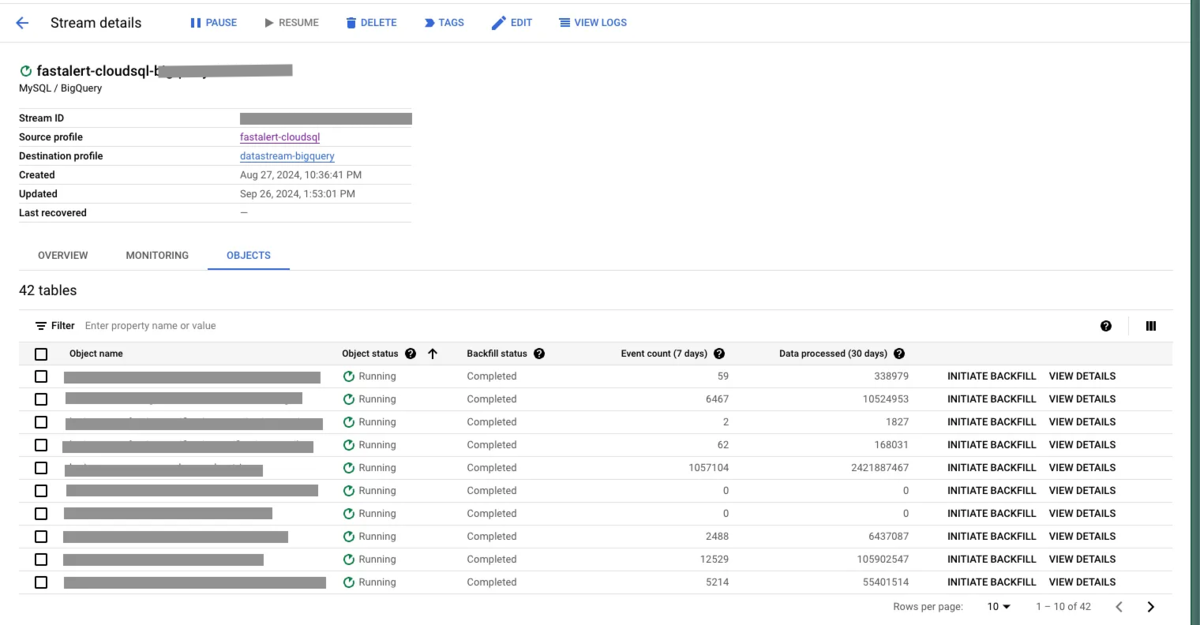
該当テーブルを転送対象から外した結果、費用は想定範囲内に抑えることができました。
課題3 同期テーブルのパーティション分割
BigQuery はテーブルのスキャンした分で課金されるため、テーブルを時間(日付)でパーティション分割するのは一般的です。時間(日付)パーティションを指定して、必要なデータだけをクエリすることで、クエリの効率が向上し、費用面でも節約が可能になります。
これまで、FASTALERT の災害記事テーブルは daily 単位で同期しており、日付でパーティション分割を行っていました。
しかし、今回利用する Datastream はテーブルのパーティション分割をサポートしていません。
こちらのドキュメント https://cloud.google.com/datastream/docs/best-practices-partitioned-tables?hl=ja のオプション1 に従ってパーティションを設定してみました。
手順としては、以下の通りです:
- Datastream に該当テーブルの同期を止め(転送処理を完了するまで待つ)
- Datastream から出力した BigQuery テーブルを複製し、パーティション分割テーブルとして作り直す
- Datastream の同期を再開
ただし、このドキュメントに記載されている方法には、漏れがありました。
Primary Key を設定すること
ドキュメントには Primary Key に関する記載がなかった(最新のドキュメントのオプション2には関連する記載があったが、オプション1の手順には記載なし)
BigQuery の CDC は、Primary Key が前提条件となっています。
上記の Step 3 で Datastream を再開したあと、転送先のテーブルに Primary Key が設定されていないとエラーが発生します。
CREATE TABLE dataset.partitioned_table (
'id' INT64,
'name' STRING
'update_date' DATETIME,
'datastream_metadata' STRUCT<'uuid' STRING, 'source_timestamp' INT64>,
PRIMARY KEY ('id') NOT ENFORCED
)
PARTITION BY TIMESTAMP(update_date)
上記の例のクエリのように Primary Key を定義するため、テーブルをもう一度作り直すことになりました。
max_staleness を設定すること
Primary Key と同様に、Datastream が自動生成したテーブルでは max_staleness が設定されていますが、手動で作り直したテーブルでは自前で設定しなければなりません。
max_staleness が設定されていない場合、デフォルト値の 0 が設定されます。この状態では、クエリを実行するたびに BigQuery は最新の結果を返すため、目標のパーティションだけでなく、Stream Buffer にあるデータも含めてスキャンされてしまいます。
これにより、パーティションが設定されていても、予想より多くのクエリスキャン量が発生します。
この設定に気づくまで、半日 max_staleness が 0 の状態で Datastream を走らせていたため、かなり無駄な費用が発生してしまいました。
まとめ
今回は、Google Cloudのデータ同期ツール「Datastream」を使用して、Cloud SQLからBigQueryへのデータ同期において実際に直面した課題を記述しました。
Datastreamは非常に便利であり、導入することで、従来はデータベースにアクセスする必要があったデータにBigQueryから簡単にアクセスできるようになりました。特に、リアルタイムでデータを同期できる点は大きな利点であり、これによりデータの可用性と分析効率が大幅に向上しました。
参考:
https://cloud.google.com/datastream/docs/private-connectivity?hl=ja https://cloud.google.com/bigquery/docs/change-data-capture?hl=ja#prerequisites https://cloud.google.com/bigquery/docs/change-data-capture?hl=ja#manage_table_staleness https://www.googlecloudcommunity.com/gc/Data-Analytics/Problem-with-partitioned-table-in-BigQuery-and-streaming-buffer/m-p/712332