はじめまして。JX通信社でデータアナリストをしている @nrtaking です。
弊社では、7/23〜8/8に行われた東京オリンピック、8/25〜9/5に行われた東京パラリンピックにあわせて関連した日本語ツイートを全量収集し、Twitter Japanなど各社に提供していました。
内容に関する簡単な分析についてはプレスリリースでお伝えしているので、そちらもあわせてご覧ください。
実はこのツイート収集システムは、2週間ほどでほぼゼロから立ち上げたものでした。 今回は五輪関連のツイート収集を支えた技術について紹介します。
叶えたかった要件
- 五輪に関するツイートを、NTTデータの提供するAPIからストリームで受け取り続ける
- ツイート量などの統計情報やRTが多いツイート情報をダッシュボードの形で見ることができる
- 上記を(ほぼ)リアルタイムで実現できる
実はこの取り組みにあたり、システム全体を一から構築する必要がありました。
提供が決まったとき、データ提供までのタイムリミットは約2週間。開催までは否定的な意見が目立っていたとはいえ、オリンピックが実際に始まると盛り上がることは容易に想像できました。 フルスクラッチで全部を作ることは早々に諦め、GCPのマネージドサービスをできるだけ活用する方向に切り替えました。
全体のアーキテクチャ
使ったサービス
- Compute Engine
- Cloud Pub/Sub
- Cloud Dataflow
- Cloud Storage
- Cloud Composer
- BigQuery
- Google データポータル
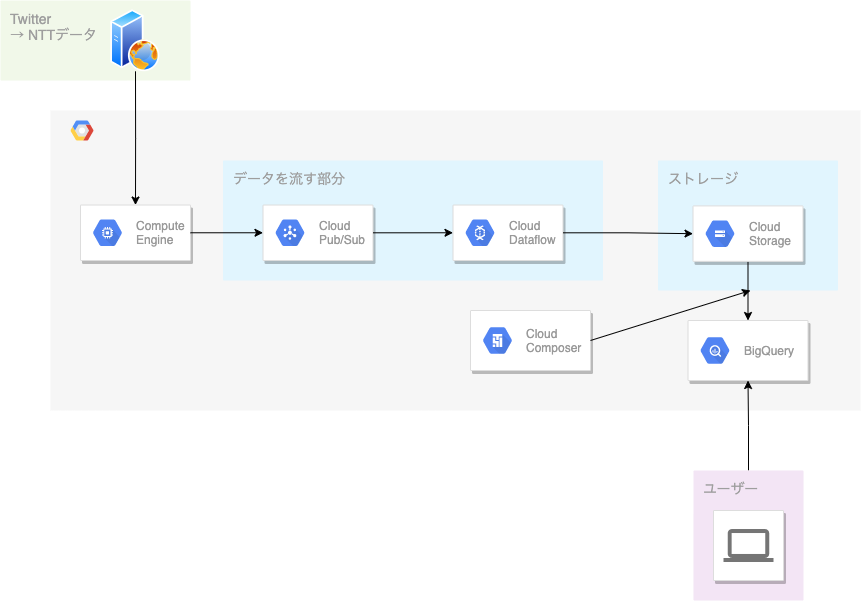
それぞれの役割
Compute Engine
- ツイートを収集し続ける役割。
- 弊社で提供しているプロダクトFASTALERT(ファストアラート)で同じような収集システムが存在していたので、そのコードを再利用しています。
- といっても、コード自体は大したものではなく、全部で100〜200行程度。
- 収集システムは Docker 化しておいて、インスタンス上で Docker コンテナを立ち上げています。Compute Engine には簡単に Docker コンテナをデプロイできる機能があるので、これを活用しました。
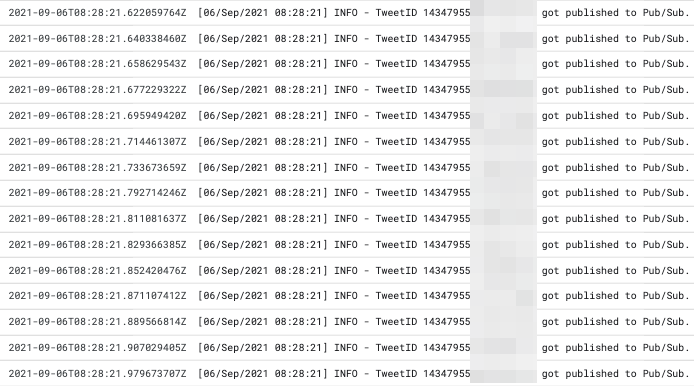
Cloud Pub/Sub
- GCE で動いてるシステムからツイートを一つずつ受け止め、Cloud Dataflowに一つずつ流してあげる役割。
- ここのリクエスト数のメトリクスを Datadog で監視してあげることで、 GCE がツイートを収集し続けられているか、死活監視していました。
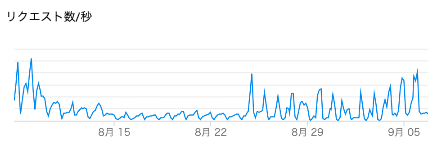
この「リクエスト数」を死活監視に使ってました
Cloud Dataflow
- Pub/Sub から受け取ったツイートを、5分おきに Cloud Storage に吐き出す役割。
- Dataflow には Pub/Sub から MongoDB など、さまざまなテンプレートが用意されています。今回は Pub/Sub から Cloud Storage に吐き出すテンプレートを使用しました。
- ここから BigQuery に直接吐き出す選択肢もありましたが、データのスキーマ設定で沼ったので諦めました。
- Cloud Storage に吐き出す時は JSONL の形式にしてました。
Cloud Storage & BigQuery
- 社内のデータ基盤では Cloud Storage から BigQuery にロードする構成を取っており、同様の構成としました。
- Airflow で動かすDAGの定義のために50行くらいコードを書きましたが、これも社内のコードを再利用する形。
- 社内のデータ基盤についてはこちらも見てみてください!
- 5分おきにロードされるよう設定しましたが、重複排除の仕組みを作るのが少し面倒でした。
- 新しく Cloud Composer のクラスタを立てると維持費が高くなってしまうため、先述したデータ基盤のクラスターに相乗りすることで維持費を節約しました。
Google データポータル
- 簡単な可視化であれば、これで十分です。
- 今回は特に、ダッシュボードの利用者も Google Workspace を使っていたため、重宝しました。
- フロントの開発が必要なかったのが非常によい。
気になる点① 処理性能と安定性
もちろん時間帯ごとにツイート数に差があるのですが、
- 平均すると1秒あたり40ツイート程度を処理し続けました。
- 結果的に、 五輪の2週間で約5000万ツイートを処理 することができました。
死活監視も仕込んでましたがアラートが来ることもなく、安定性もバッチリでした。
気になる点② 値段
実際に動かす前は結構気にしていた点で、動かし始めた当初は費用がかさんでいたのですが、いろんな工夫をした結果、1日あたりの費用は数十ドル程度までおさえることができました。

- Compute Engine のインスタンスタイプを可能な限り下げる
- 特にお金がかかる Cloud Composer は既存プロジェクトのものを使う
といった工夫をしています。特に後者の工夫がなければ、費用は跳ね上がっていたと思います。
それでもなお課金額が多いサービスは
- Cloud Monitoring (Compute Engine のロギング)
- Cloud Dataflow
の2つです。ツイートごとにログを吐き出す形にしていたため、前者は流量に比例するものですが、後者はCPUやストレージが常に必要になる以上、その動作時間に対して常に費用がかかり続けます。
Cloud Dataflow の実体は Compute Engine 上にあり、設定時に割り当てるインスタンスタイプを選ぶことができるのですが、 g1-small など、共有コアを使う(安価な)インスタンスタイプを割り当てられないことも費用がかさむ要因です。
立ち上げてみて
2週間という短い期間にもかかわらず、社内のリソースとGCPのマネージドサービスを使うことで、大量のデータを処理できるシステムを作ることができました。
GCPは偉大です!